







 Рейтинг: 4.3/5.0 (1808 проголосовавших)
Рейтинг: 4.3/5.0 (1808 проголосовавших)Категория: Инструкции
Попробую "на пальцах" объяснить как это все работает. Много подробностей будет опущено. Цель данной статьи - получить понимание принципов работы. (В свое время мне именно этого и не хватало, (надо было начать пользоваться вникая в тонкости по ходу дела))
Подробно можно читать тут http://git-scm.com/book/ru/
Итак - установка:
1. Нужно установить сам git http://git-scm.com/downloads (качаем под свою ОС - инсталим)
2. Прописываем PATH - C:\Program Files (x86)\Git\cmd (ну. или куда он у вас там поставился)
Что такое VCS и для чего они нужны - гуглим, статей на эту тему полно.
Git (не путать с GitHub) создает локальный репозиторий в папке с вашим проектом. (скрытая папка .git) который будет хранить версии ваших кодов.
Управлять этим репозиторием можно через командную строку, или средствами ide (если она поддерживает работу с git'ом)
Происходит это следующим образом:
- Вы создаете проект.
- Вы создаете репозиторий (команда из командной строки (см доки по гиту) или соответственное меню в IDE.
- Пишете классы, файлы и т.д вашей программы.
- Делаете Commit (помещаете в созданный локальный репозиторий то, что вы "натворили")
- Далее можете создать новый branch (ветку) (а можете и не создавать )
- Внести изменения в код, закоммитить. Вернуться к предыдущей ветке. ну и т.д. (Как всем этим пользоваться полно доков и статей.)
Помимо локально репозитория существуют еще и удаленные репозитории. Они существуют совместно с локальным репозиторием и отдельно от него работать с ними не получится.
Пример таких репозиториев GitHub и bitbucket.
Работа с ними это, по сути, синхронизация вашего удаленного репозитория с локальным.
Вам нужно зарегистрировать аккаунт на одном из этих сайтов.
Затем создать новый репозиторий. (под каждый проект свой) (Название удаленной репы не важно).
Специальной командой сделать привязку вашего локального репозитория к удаленному. (Ее можно найти на стартовой странице только что созданного удаленного репозитория)
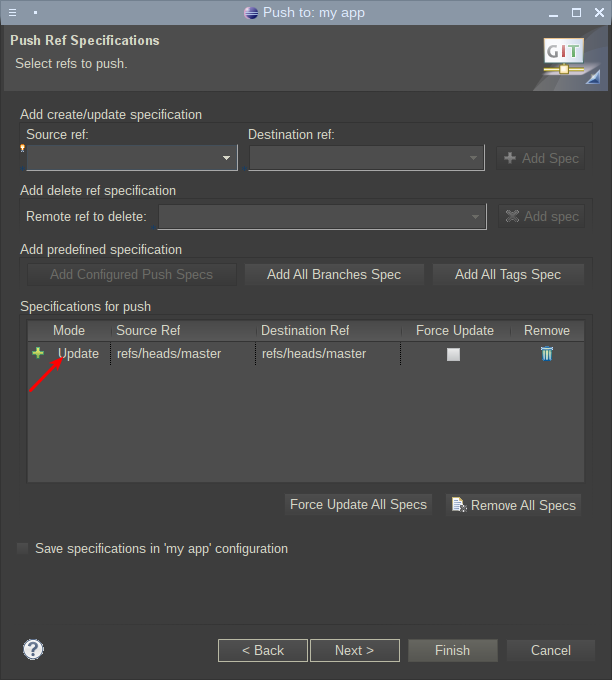
Выглядит она примерно вот так:
Кликните здесь для просмотра всего текста
После "привязки" удаленного репозитория, нужно выгрузить в него коммиты из локального репозитория.
Для этого делается Push (см доки по гиту или IDE)
После пуша ваш проект появляется на соответствующем сайте. Вы можете дать ссылку на него своим друзьям. И они с помощью этой ссылки смогут легко открыть ваш проект у себя на компьютере. Но те изменения что они сделают в проекте они останутся только в их локальных репозиториях. Внести изменения в ваш удаленный репозиторий у них так просто не получится. (он же для них readonly)
Для того что бы внести изменения в ваш репозиторий им нужно сделать Fork. (Зайти на сайт и там сделать Fork вашего проекта).
Fork - это клонирование(копирование) вашего проекта на аккаунт к другу.
Далее друг импортирует созданную копию к себе на компьютер (при этом из удаленного репозитория копируются файлы и создается локальный репозиторий)
Друг вносит изменения
Делает коммит (в локальный репозиторий)
Делает пуш в удаленный репозиторий (копию вашего проекта)
А затем может сделать Pull в ваш репозиторий (тот с кого был сделан форк).
Когда он сделает Pull вам на сайте придет оповещение. (Запрос на изменение вашего репозитория)
Вы можете его просмотреть, принять или отклонить.
Я работаю в IDEA, сделаю в ней простой пример.
Создаю новый проект.
Создаю локальный репозиторий
IDEA создает служебные файлы (.idea, *.iml), которые мне не хотелось бы добавлять в репозиторий (ведь далеко не факт, что другие пользователи будут открывать мой проект в IDEA) для того что бы их убрать гуглим gitignore
в IDEA я делаю так:
(внизу IDE)
а полезное добавляю (это в том случае, если я создаю локальный репозиторий после того как уже что создал)
Далее делаю коммит
Созданный класс добавлен в локальный репо.
Теперь выгрузим это все на гитхаб.
Для этого создаем на сайте новый репозиторий. Я сделал на гитхабе и назвал его HelloWorld.
Ищем там команду привязки и вводим ее в командную строку. (я воспользуюсь Терминалом IDEA)
И делаем Push
Проект появился на гитхабе.
https://github.com/reisal78/HelloWorld.git
Другие пользователи могут сделать с него fork
и открыть у себя в ide
Буду признателен за правки, дополнения и т.д =) Все исправлю, все добавлю =)












Bitbucket + Eclipse. Инструкция по настройке от А до Я.
После перехода с Windows на Linux и установки Eclipse 4.3 Kepler у меня появилась необходимость добавления своего приложения для Android в систему контроля версий. Разрабатываю я его пока один и контроль версий нужен, чтобы видеть историю изменений и иметь возможность откатиться на более раннюю версию, плюс это хорошее и удобное резервное копирование проекта.
Решение данной задачи я собирал в нескольких местах, после чего родилась идея написать подробное руководство.
Делать свой первый проект открытым я пока не планировал, поэтому вместо популярного GitHub выбрал Bitbucket. Он позволяет делать любое кол-во открытых и закрытых репозиториев совершенно бесплатно.
Отмечу, что в инструкции очень много скриншотов!
Регистрация на Bitbucket
Процесс регистрации, как это уже почти везде принято, очень прост. Всё начинается со страницы регистрации bitbucket.org/account/signup/ :
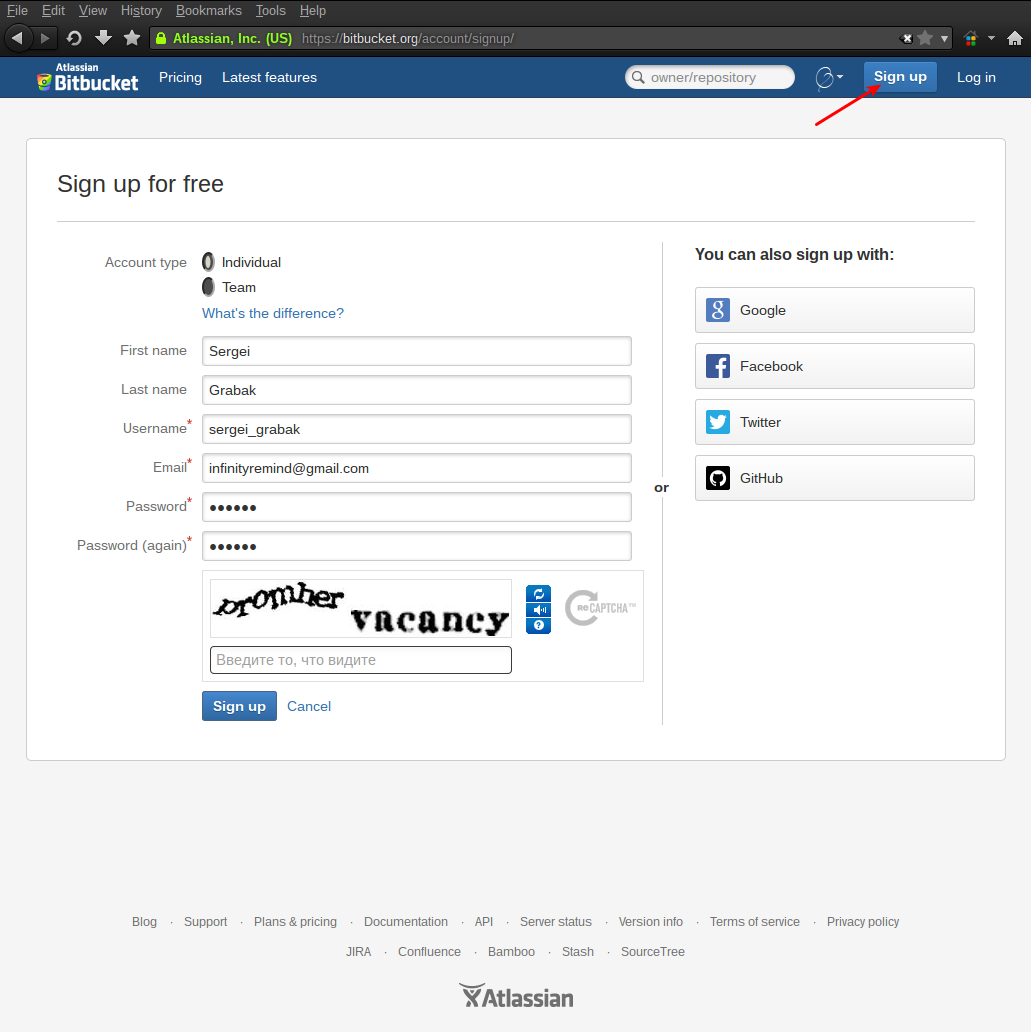
На данной странице нужно выбрать тип создаваемого аккаунта (персональный или для группы разработчиков) и заполнить остальные стандартные поля. Обращаю внимание на поле с именем пользователя (Username), в нем лучше всего написать Ваше имя, вместо прозвища, так с Вами будет проще общаться в дальнейшем.
После регистрации, на почту придет письмо с активацией аккаунта, но на данном этапе его можно пока пропустить, т. к. оно не блокирует работу с системой.
Язык интерфейс сайта можно изменить на Русский, причём перевод достаточно хороший. Сделать это можно на странице управления профилем:
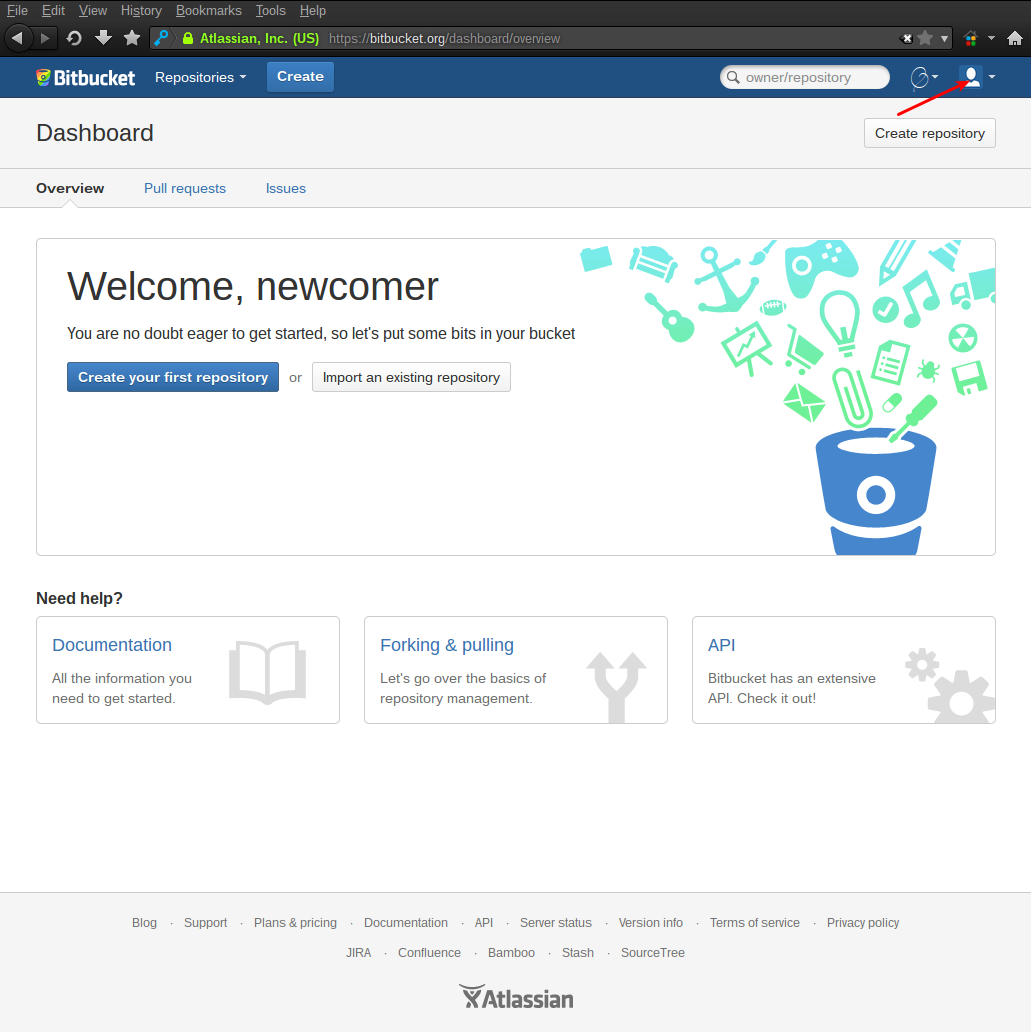
После смены языка можно приступать к созданию первого репозитория:
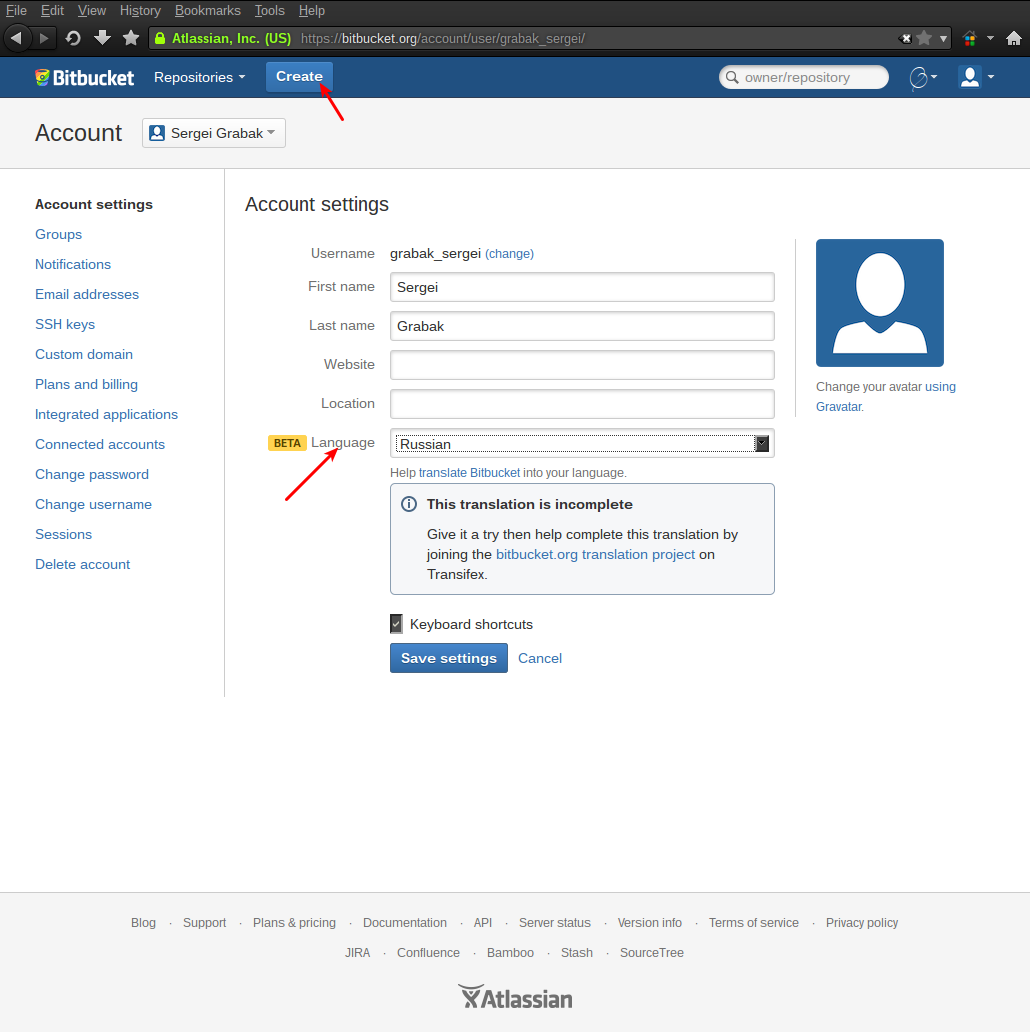
При создании репозитория необходимо указать его имя, описание, язык программирования (для подсветки синтаксиса) и, самое главное, его Уровень доступа и Тип. Bitbucket позволяет бесплатно создавать как открытые репозитории — их может просматривать и скачивать любой пользователь системы, так и закрытые — их видит только создатель и те, кому он дал на это право.
Тип репозитория зависит от той системы, с какой он в последствие будет работать. В данном случае нужно выбрать Git.
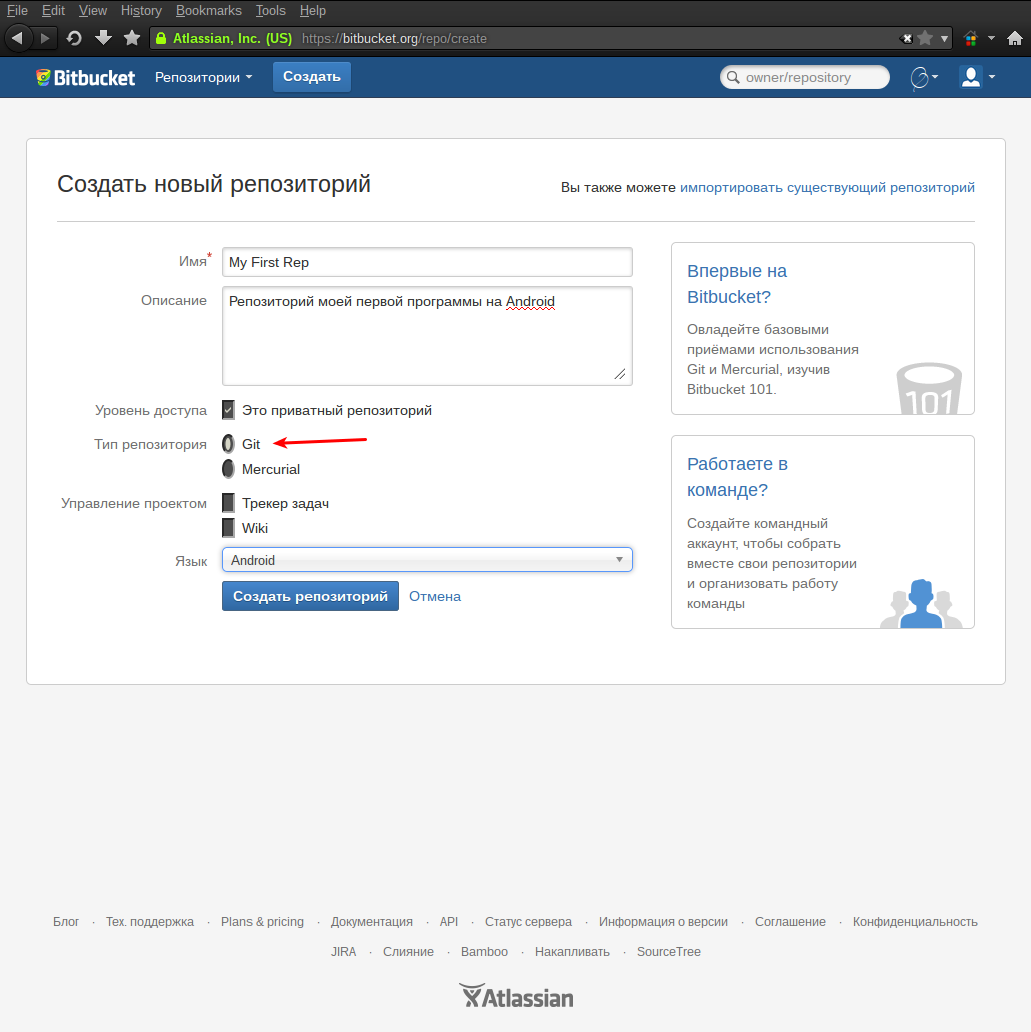
Репозиторий создан и остался последний штрих — получить на него ссылку, которая потребуется для его настройки в Eclipse. Сделать это поможет мастер начала работы с репозиторием:
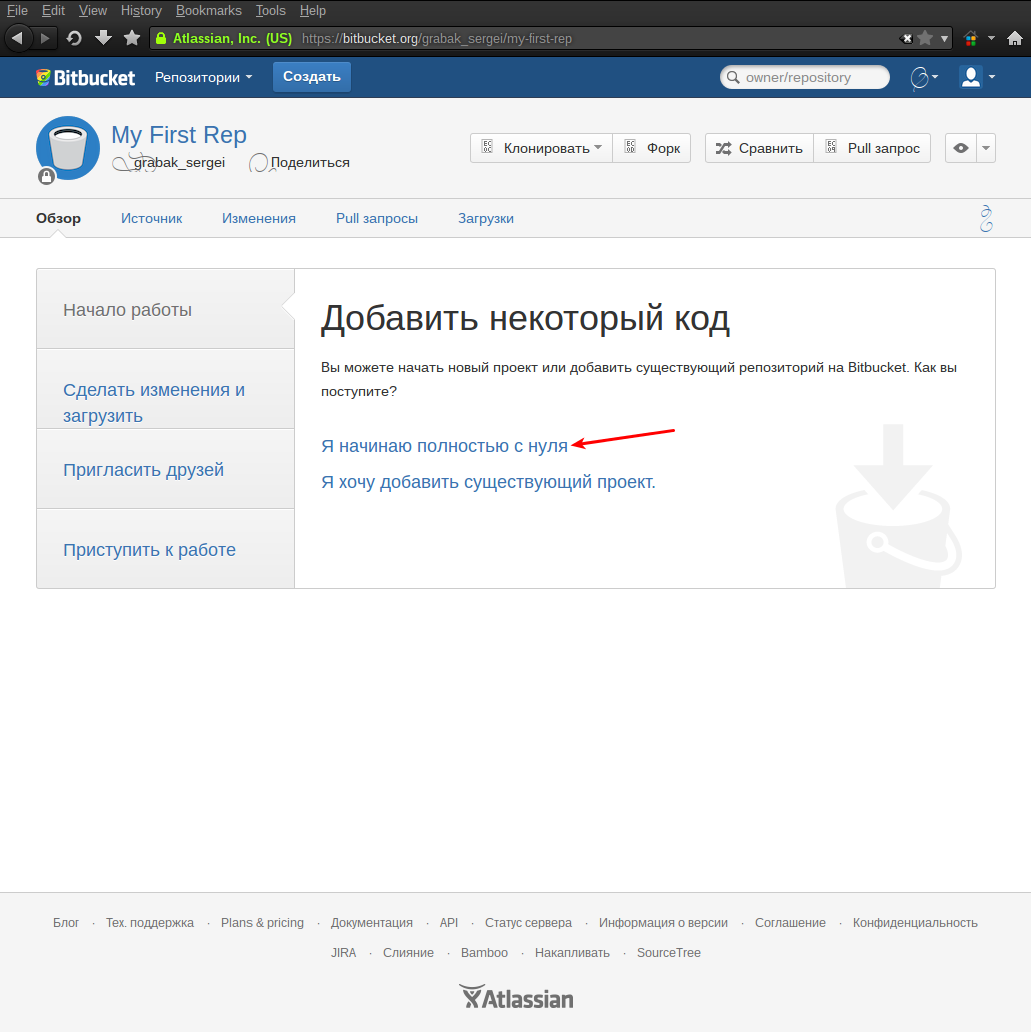
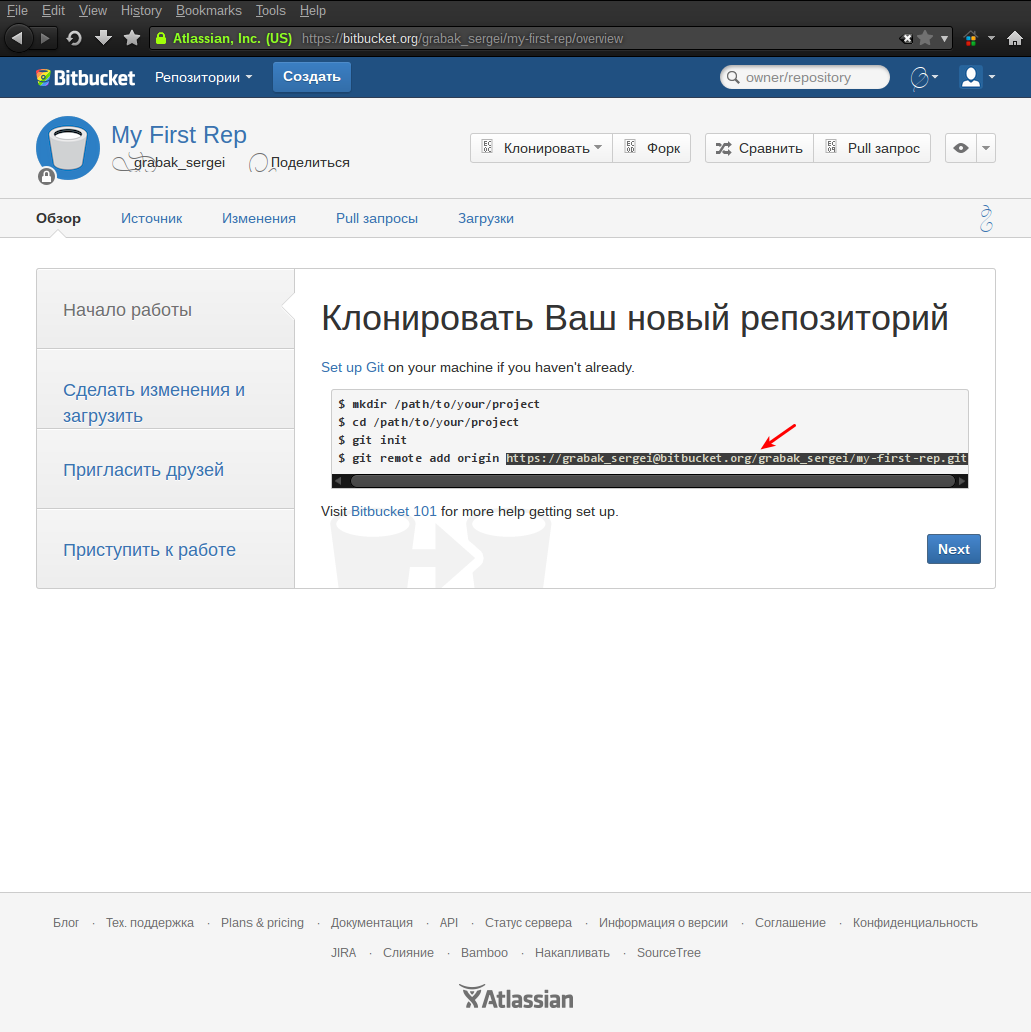
Необходимо скопировать показанную мастером ссылку и на это работа с сайтом пока заканчивается и можно приступать к настройке Eclipse.
Настройка Eclipse для работы с репозиторием на Bitbucket
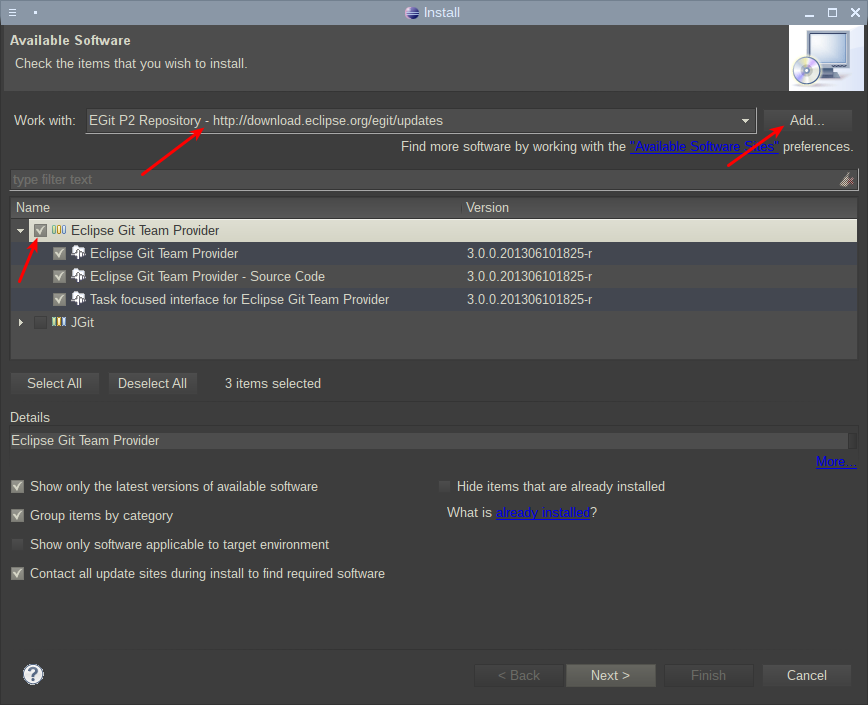
Первым этапом необходимо установить расширение EGit. Сделать это можно через главное меню:
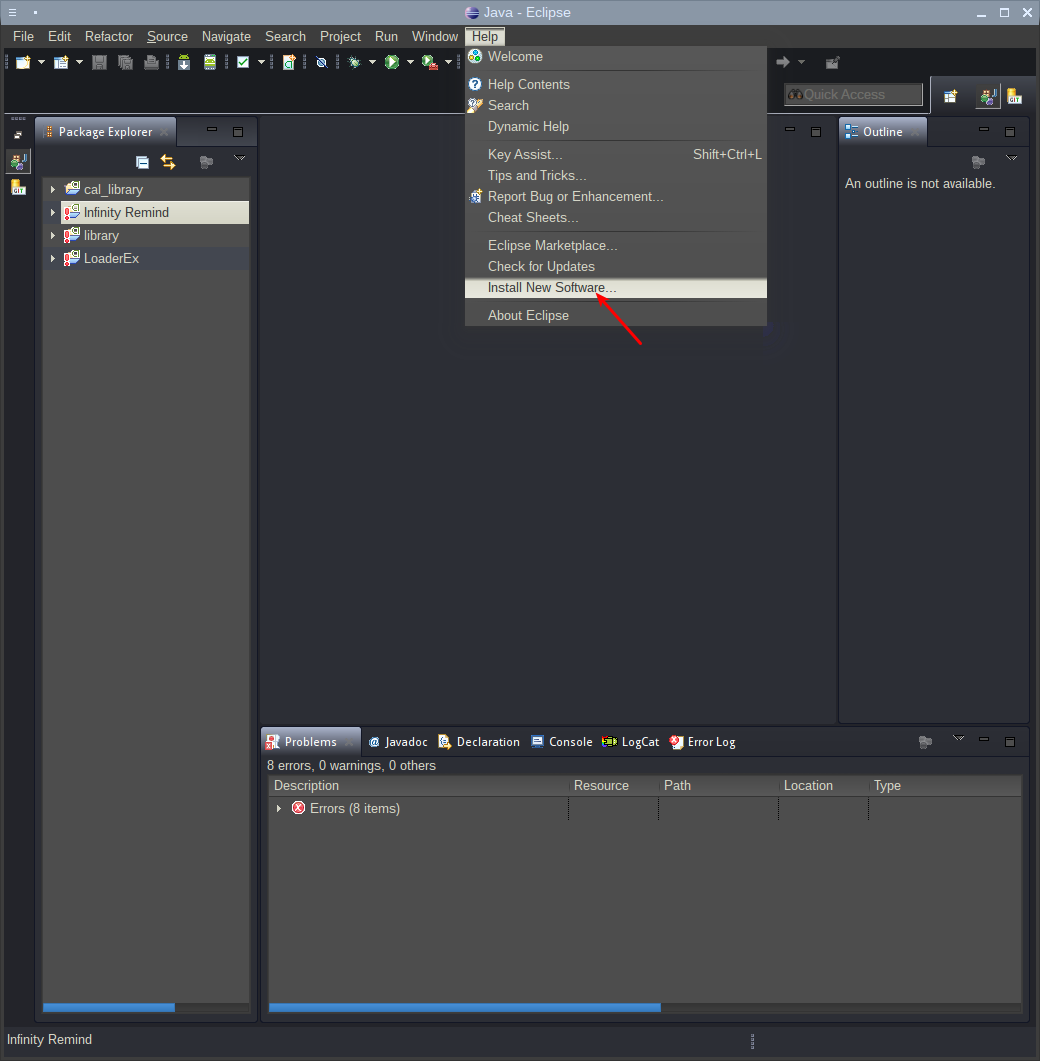
Для получения информации о расширении, а так же его установки, нужно ввести его адрес download.eclipse.org/egit/updates и нажать кнопку Add. После этого необходимо отметить галкой Eclipse Git Team Provider:
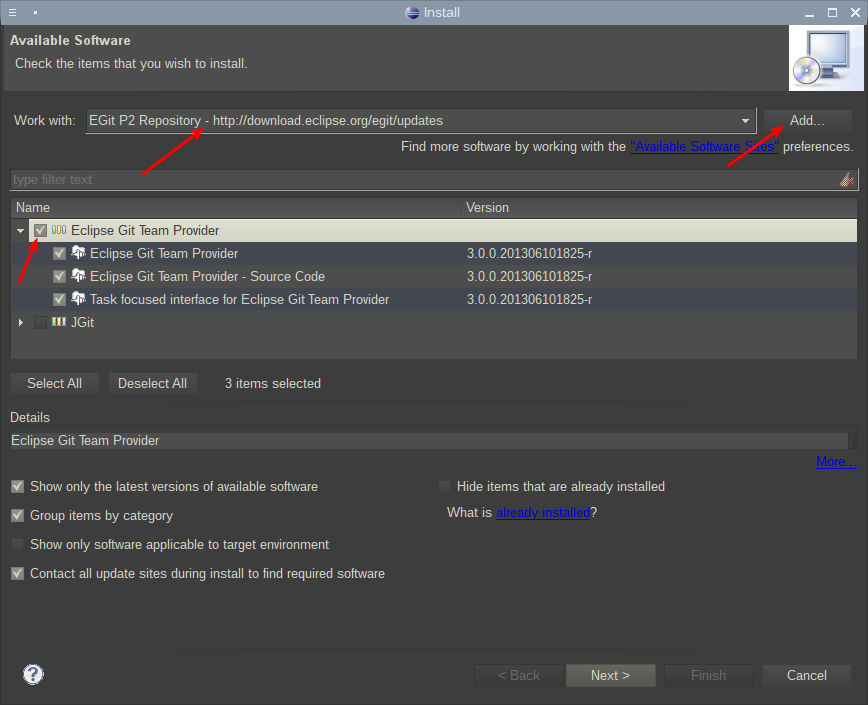
Продолжение установки потребует принятия сертификата, что можно сделать без опасений. После непродолжительной установки, Eclipse попросит перезагрузку, на что ему нужно дать разрешение.
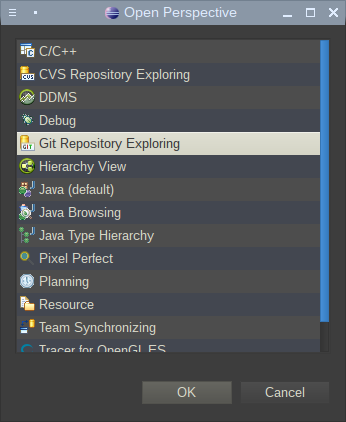
После перезагрузки плагин установлен и готов к действию. Для работы с ним нужно перейти на перспективу работы с Git репозиториями:
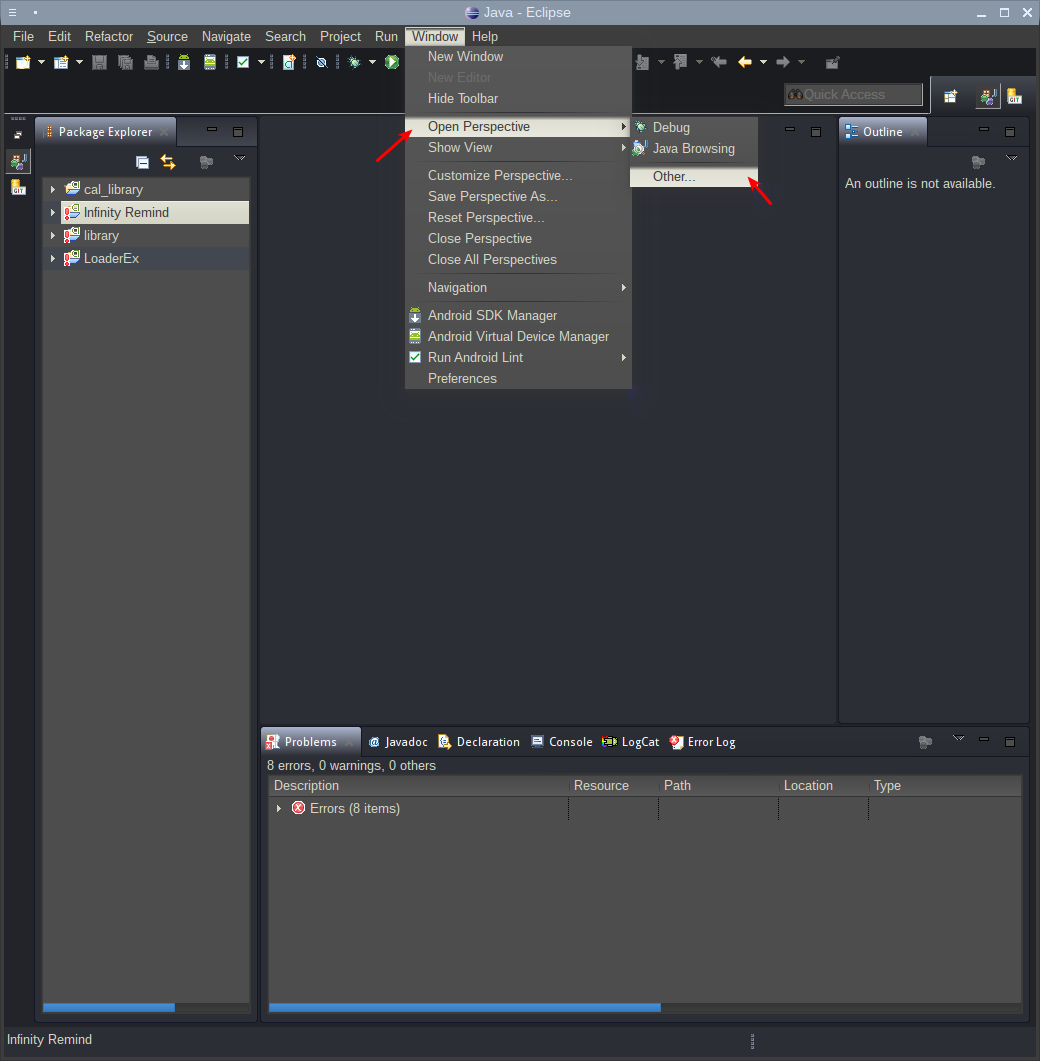
Нужная перспектива — Git Repository Exploling:
Добавить созданный в Bitbucket репозиторий можно следующим образом:
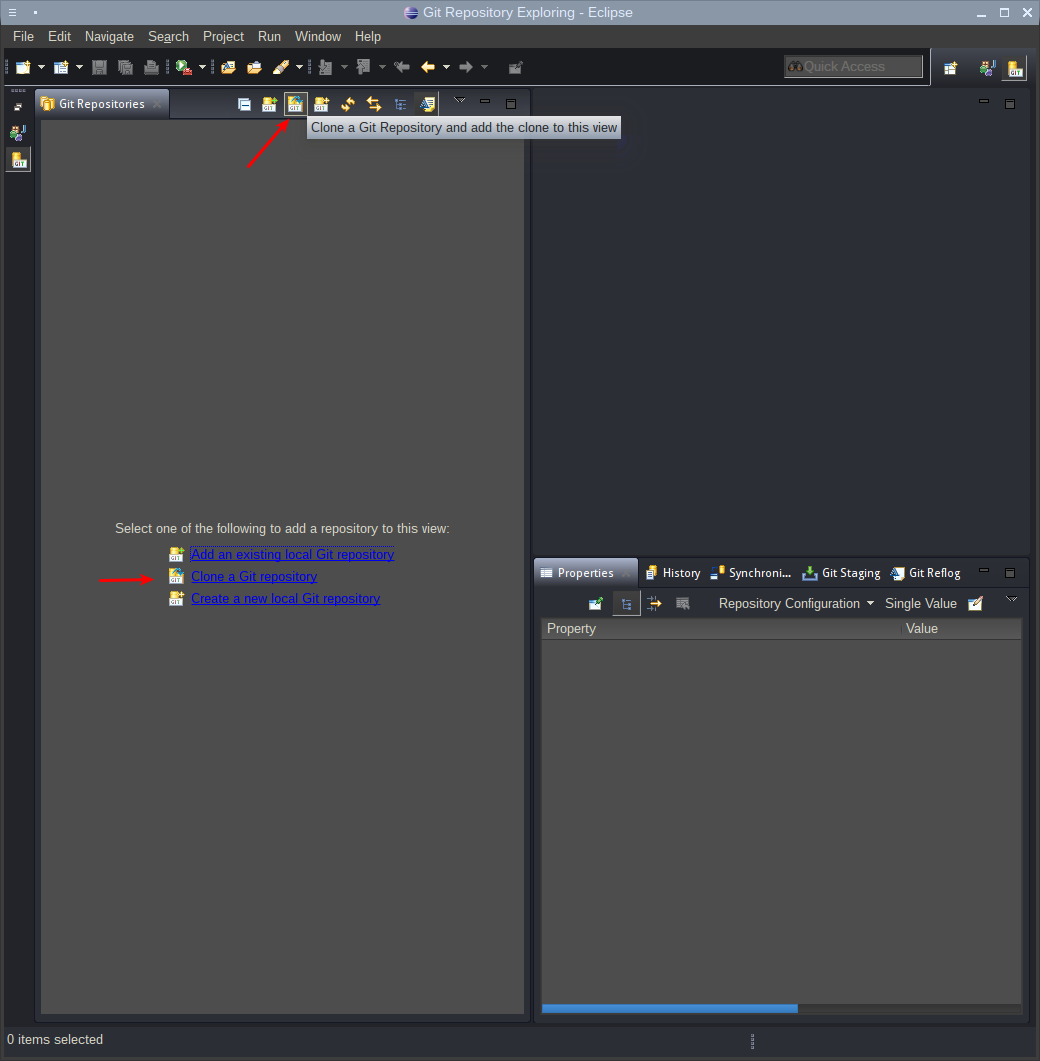
На данном этапе потребуется скопированная строка с сайта Bitbucket из первой части инструкции. После ее вставки, все поля автоматически заполнятся и останется только ввести пароль, указанный при регистрации на Bitbucket.
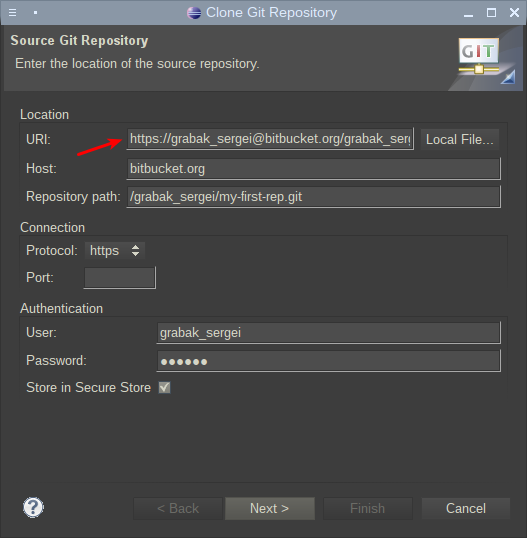
Следующее окно нужно просто пропустить. Оно говорит, что указанный репозиторий сейчас пуст, что неудивительно:
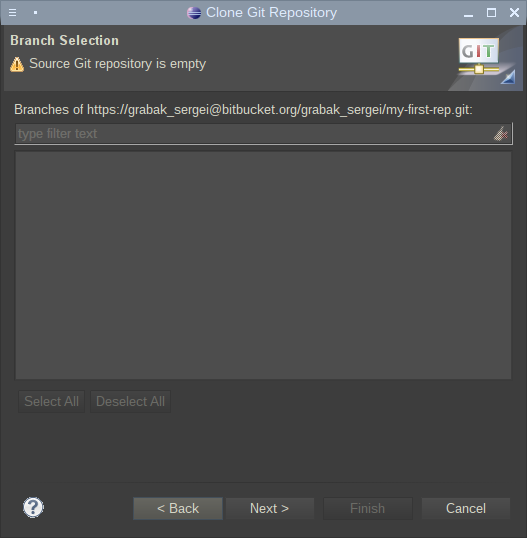
Далее потребуется ввести путь, где будет локально храниться репозиторий, а так же его имя.
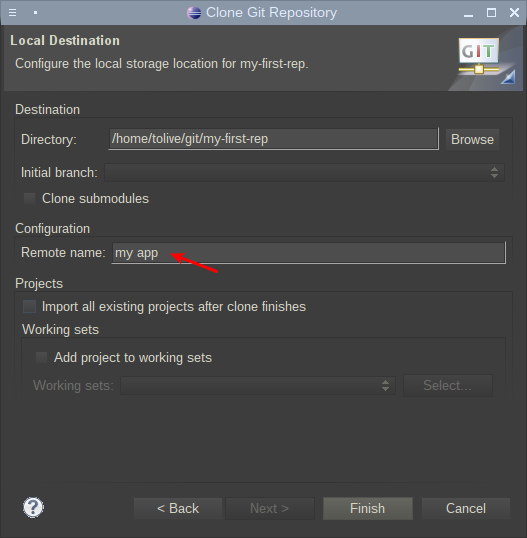
На этом этапе подключение к удаленному репозиторию на Bitbucket закончено и можно приступать к добавлению проекта в него.
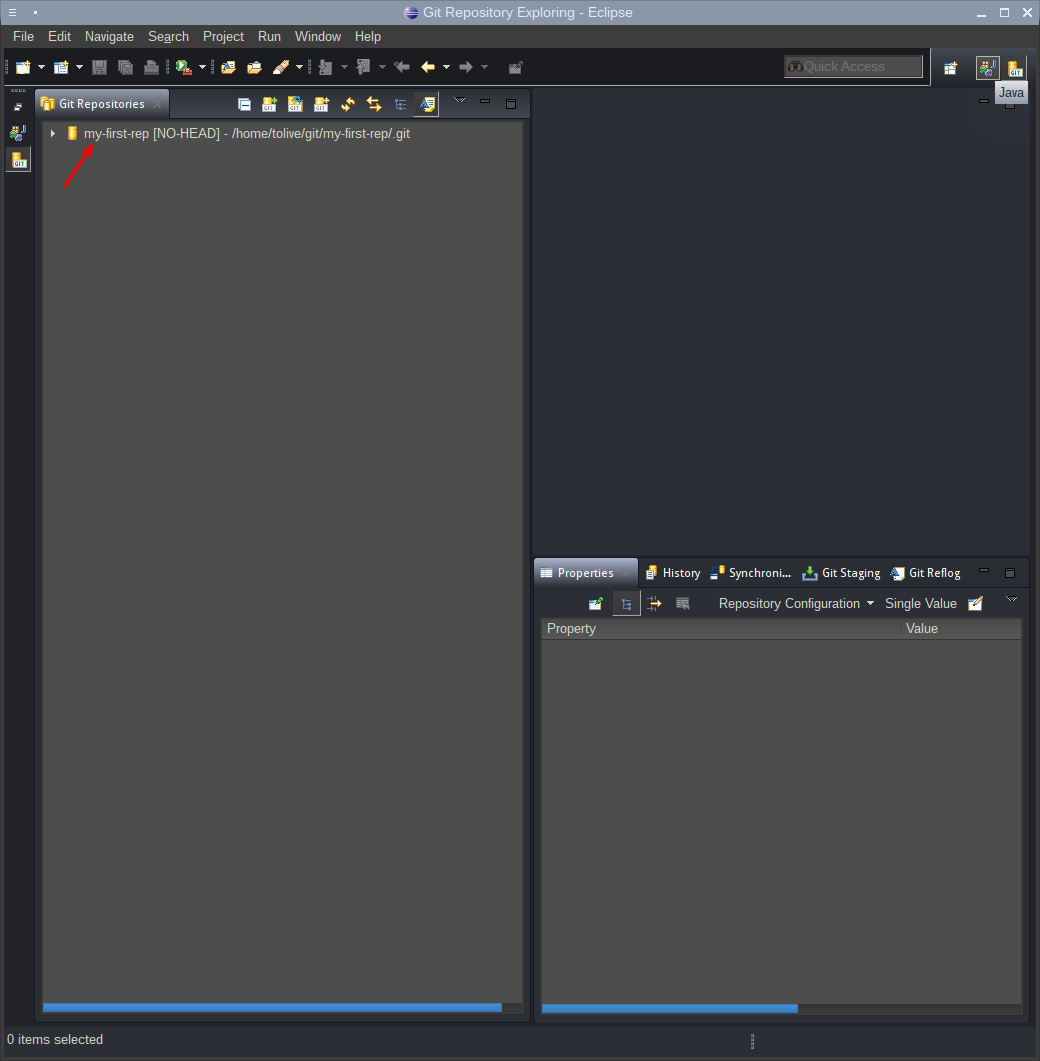
Добавление проекта в репозиторий
Репозиторий уже настроен, но пока в него не добавлено ни одного проекта.
Для этого, сначала нужно вернуться на перспективу по-умолчанию, чтобы было доступно дерево проектов. В моем случае это Java, и, в контекстном меню проект выбрать Team — Share project:
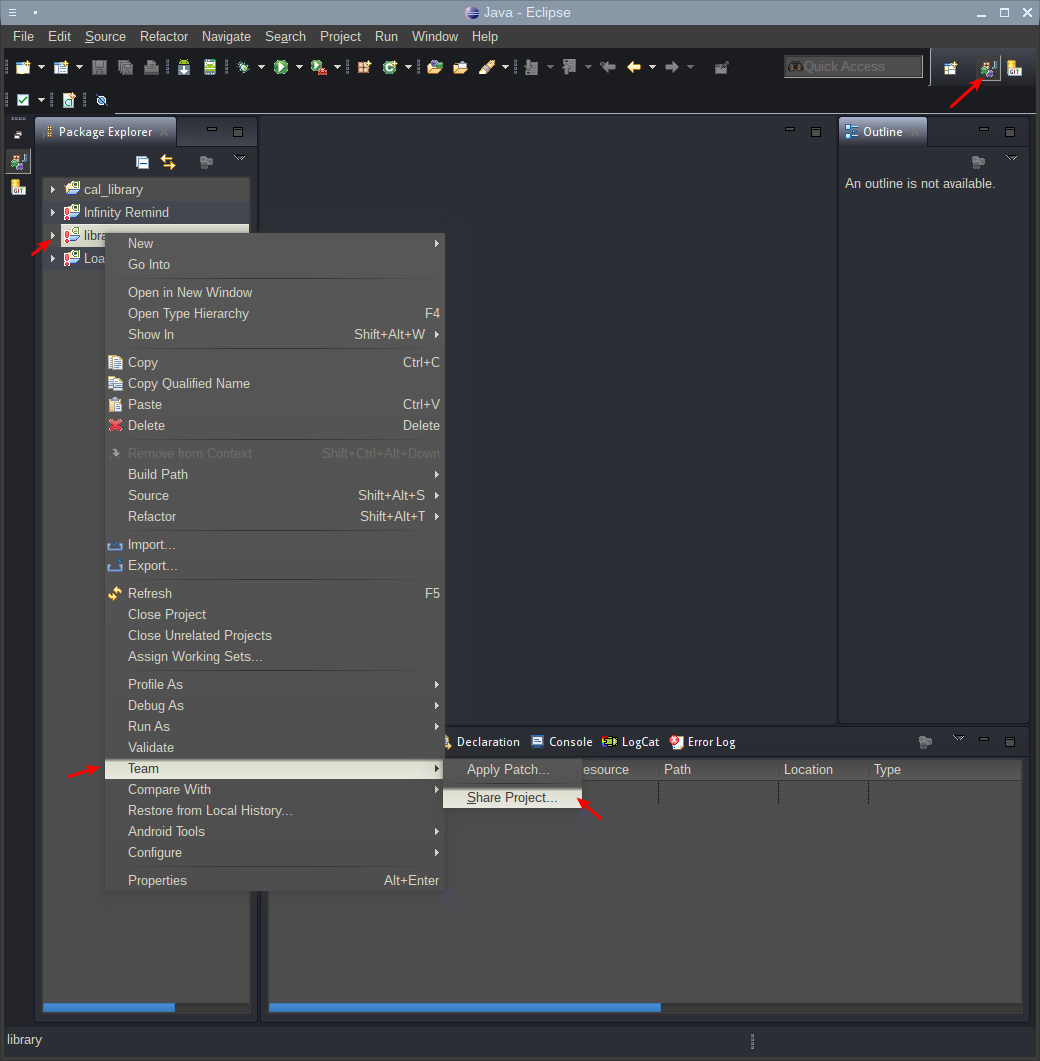
В открывшемся окне требуется выбрать Git:
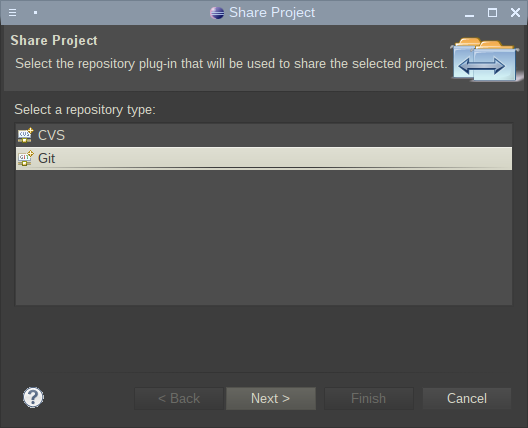
После выбора типа репозитория, необходимо выбрать его название. Скорее всего там будет только один единственный вариант:
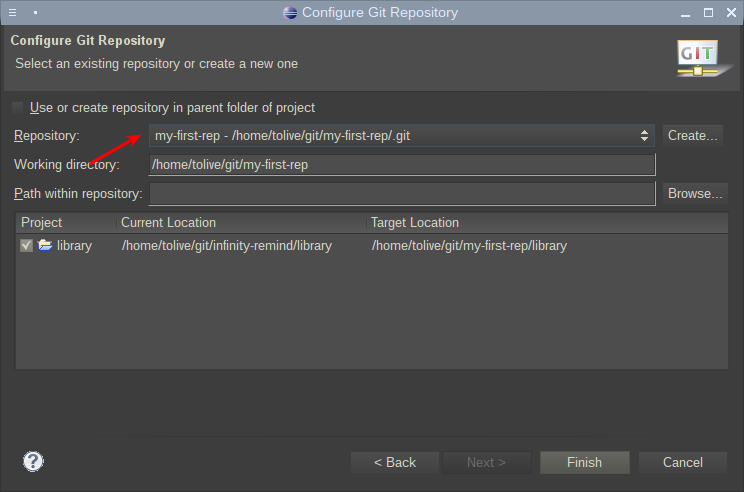
Если всё было сделано правильно, то в названии проекта появится имя репозитория и ветка, в которой он находится:
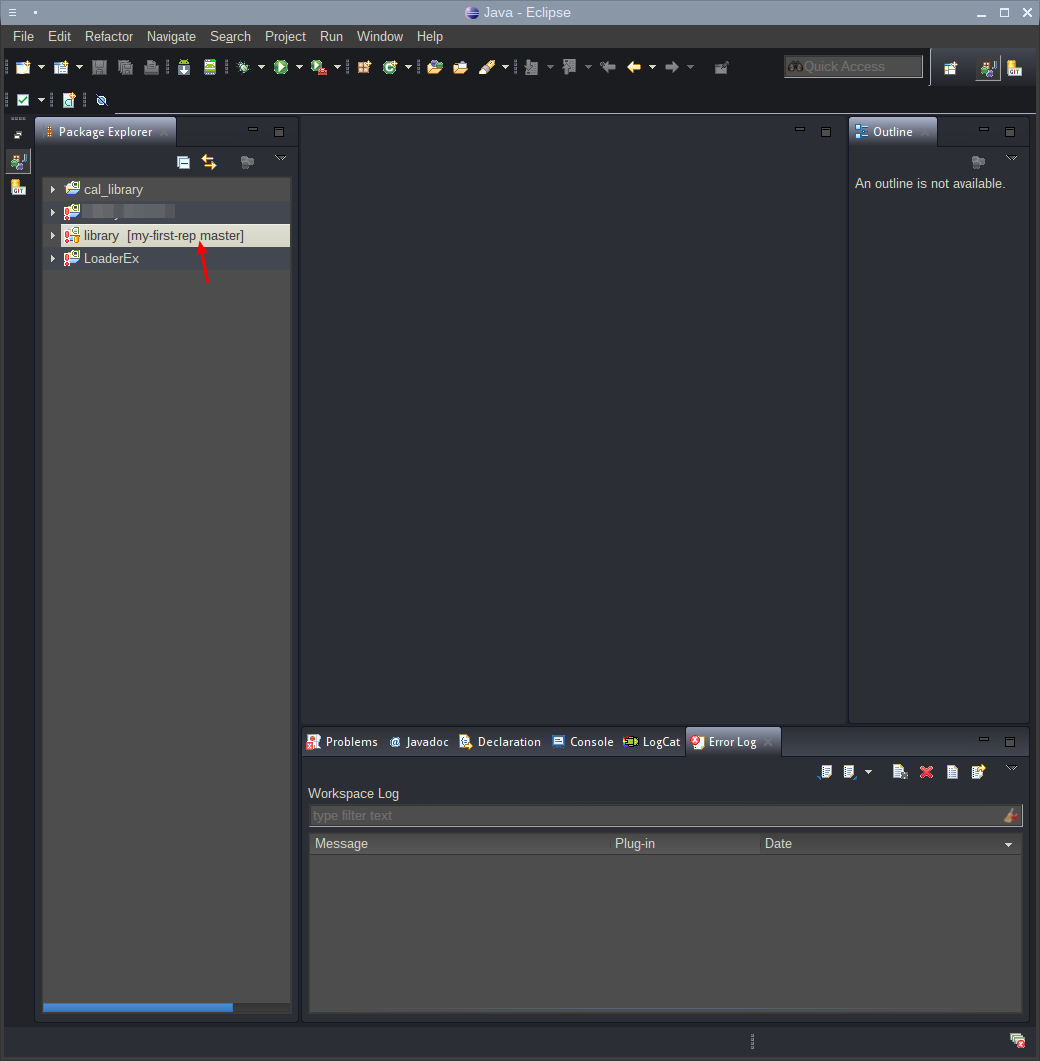
Остался последний штрих — сделать первый коммит, т. е. сохранить проект и все изменения на нем в репозиторий. Сделать это можно через контекстное меню проекта:
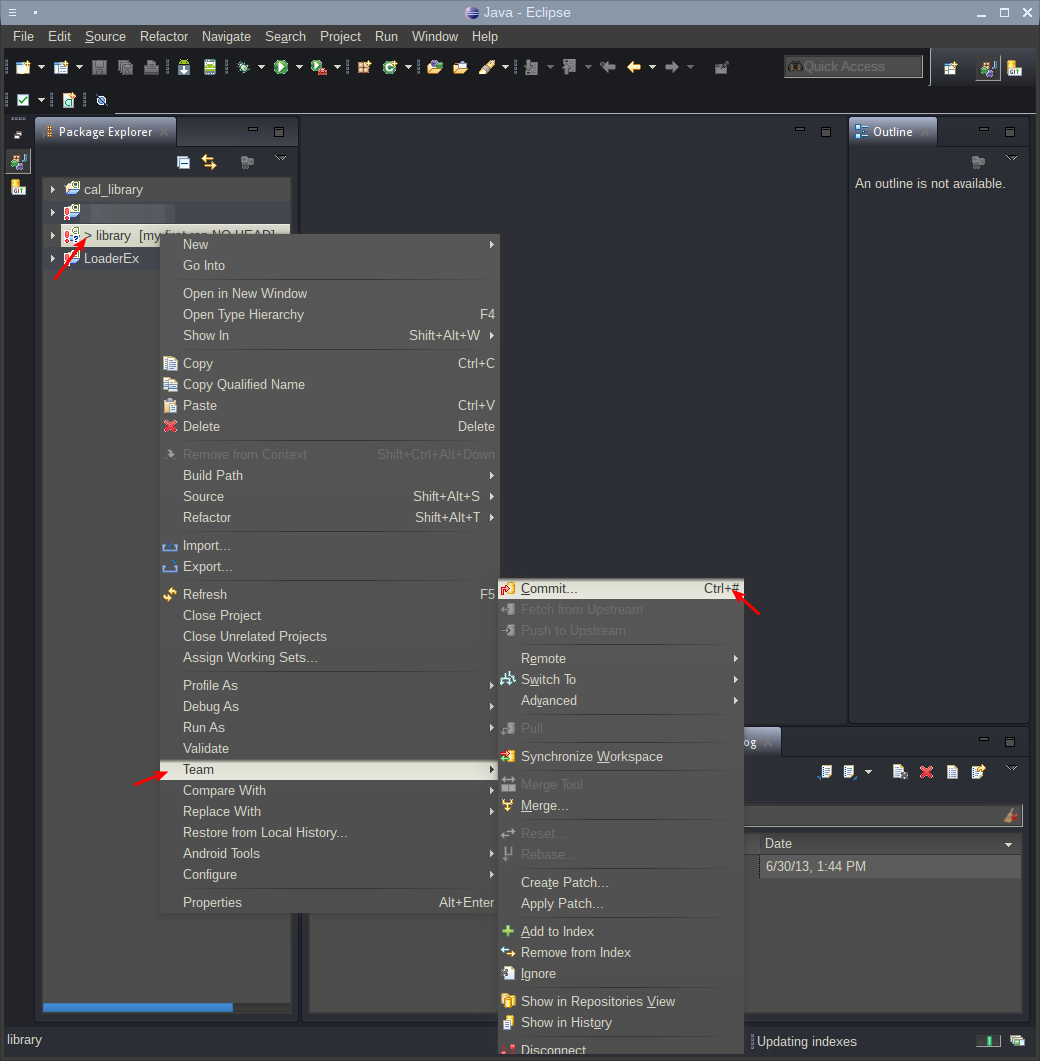
В окне коммита можно и даже нужно внести краткое описание того, что было сделано. В данном случае мы просто отмечаем, что это первый коммит. Так же необходимо выбрать файлы, которые будут загружены в репозиторий. Углубляться в тонкости того, что нужно, а что не нужно отправлять в репозиторий, пока не требуется, поэтому стоит выбрать все файлы через Select All и нажать Commit and Push:
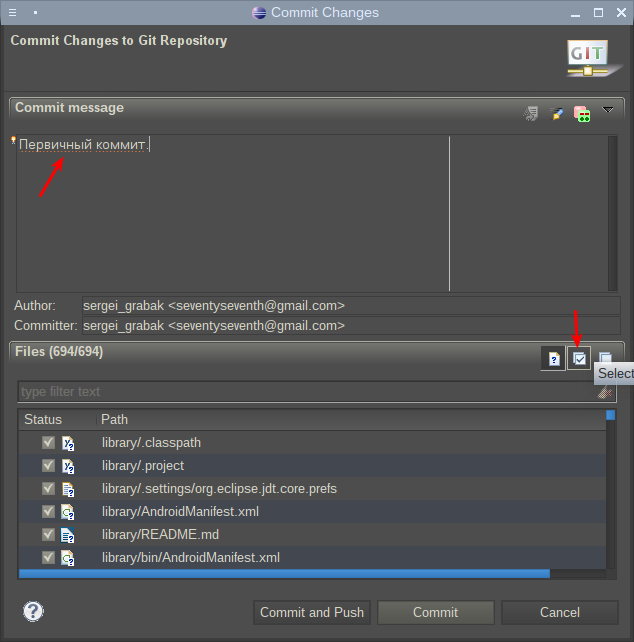
Система предложит на выбор репозиторий, в который нужно загрузить проект. Нужно выбрать созданный репозиторий:
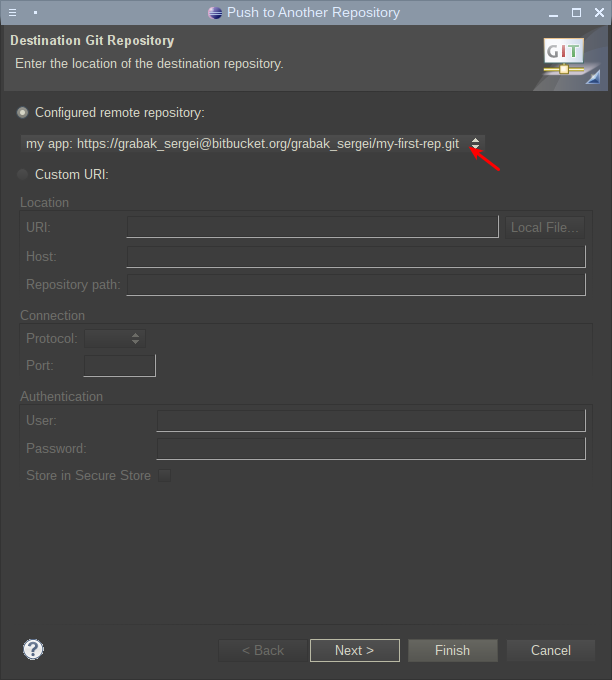
В следующем окне нужно соотнести локальную и удаленную ветку репозитория, которые будут загружены на сервер Bitbucket:
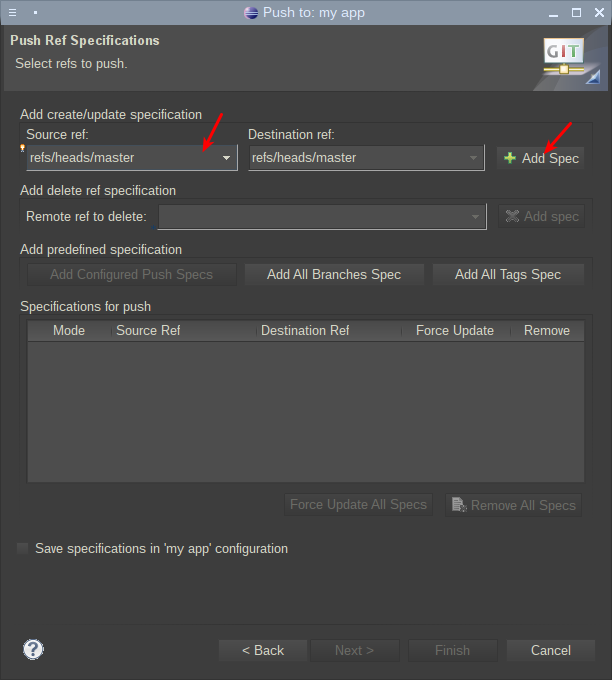
После проделанных действий и небольшого периода синхронизации проект будет загружен на сервер и, его можно будет посмотреть на сайте:
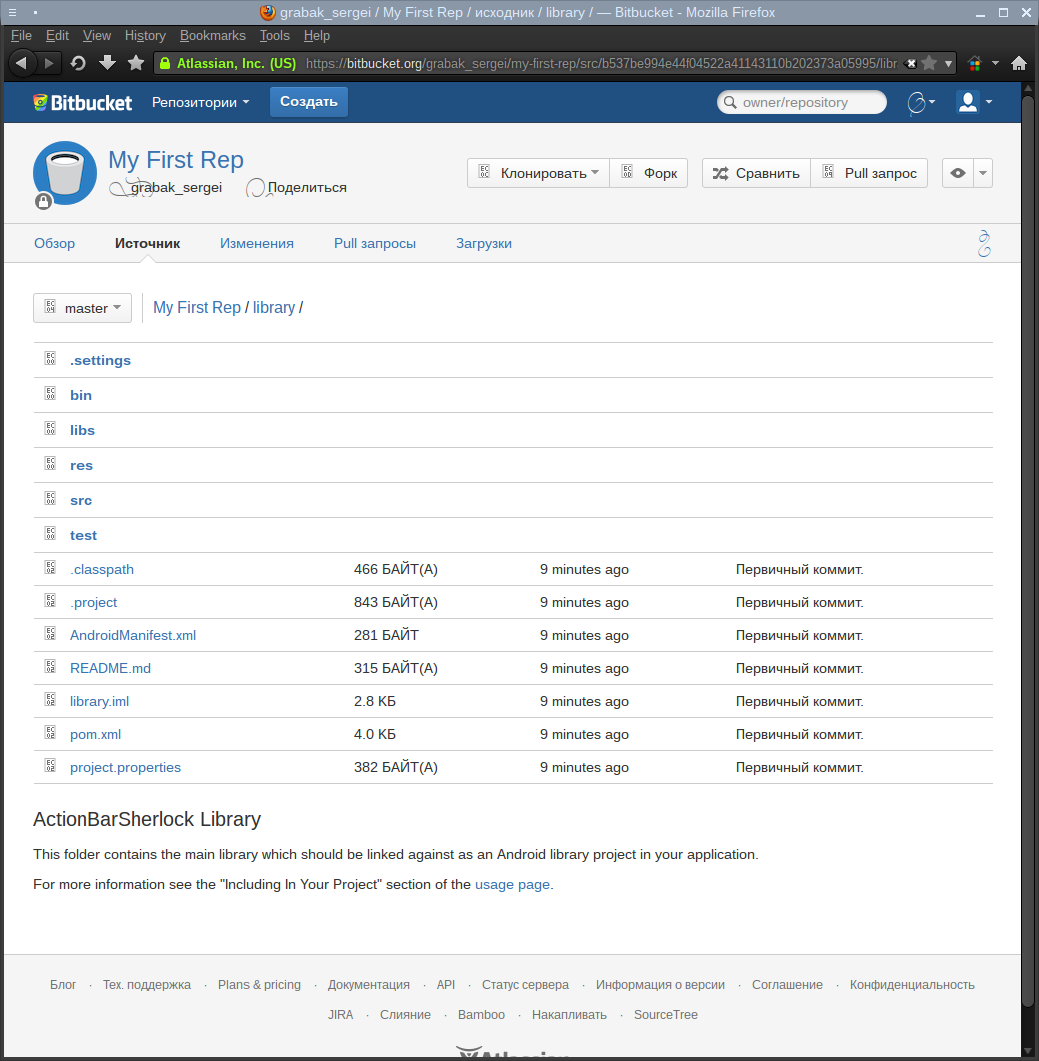
На этом базовая настройка Eclipse и Bitbucket окончена и можно приступать к работе над кодом!
P.S. Буду рад комментариям и объективной критике!
Четверг, 29 Сентября 2016 г. 12:33 (ссылка )
Всем привет! Недавно мы выпустили YouTrack 7.0, новую версию баг-трекера от JetBrains.

Что нового в YouTrack 7.0?
Теперь расскажу более подробно о каждом из нововведений.
Новая концепция Agile доскиМы полностью переработали концепцию и дизайн Agile доски — сделали ее более гибкой и легко настраиваемой и упростили управление задачами. Также мы изменили поведение работы спринтов:
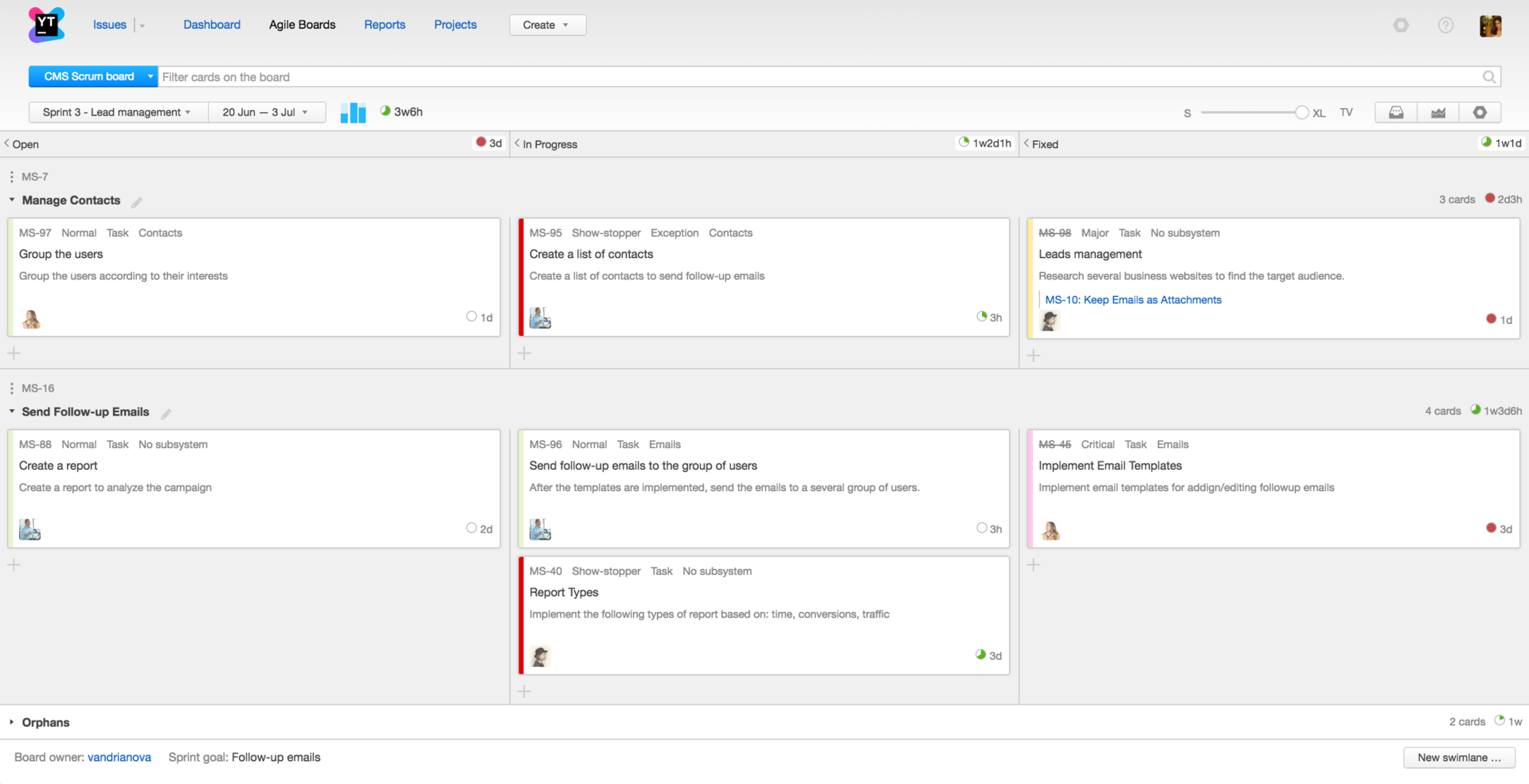
В версии 7.0 мы существенно изменили процесс управления бэклогом, сделав его максимально приближенным к работе со списком задач. Новый бэклог позволяет проще и быстрее планировать задачи: задавать сортировку вручную, редактировать поля задач, создавать задачи и подзадачи, фильтровать, строить дерево задач, использовать команды, шорткаты и поиск, а также распределять задачи по спринтам.
В предыдущих версиях YouTrack была возможность создавать черновики только на основном экране создания задачи. Теперь черновики сохраняются прямо на доске. Вне зависимости от того, где вы создаете задачу, в колонке или внутри свимлэйна, ее черновик будет сохранен. Теперь не страшно случайно закрыть браузер или окно в процессе создания задачи — вы можете легко восстановить задачу на доске. Черновики, созданные на доске, также доступны в стандартном режиме создания задачи.
Обновления в режиме реального времениYouTrack 7.0 поддерживает обновления в режиме реального времени на доске и в бэклоге. Эта функциональность полезна в командной работе, она освобождает от необходимости бесконечно обновлять страницу. Все изменения, которые происходят на доске или в бэклоге, мгновенно отражаются у вас, а также у ваших коллег.
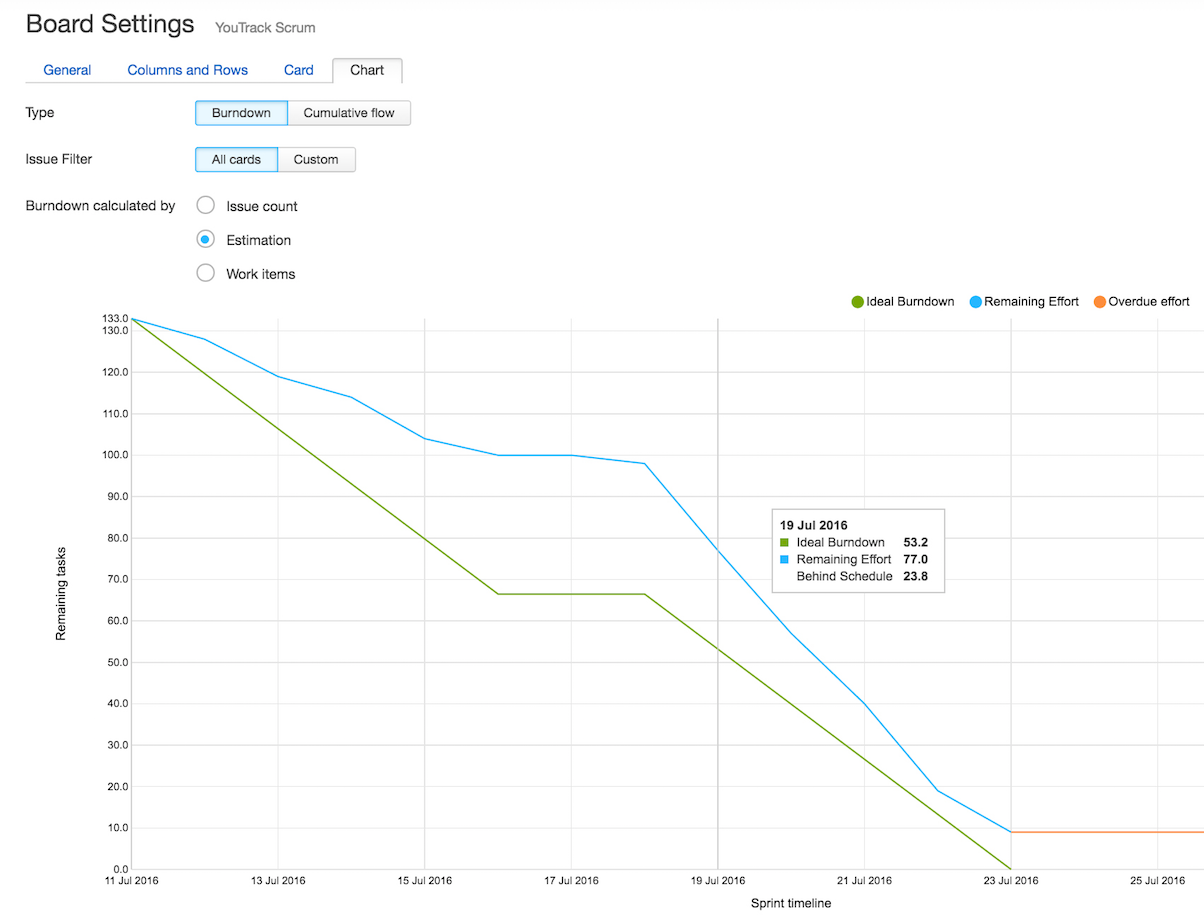
Улучшенные диаграммы Burndown и Cumulative flowВ новой версии мы также внесли некоторые изменения в диаграммы Burndown и Cumulative flow, которые доступны на доске. Теперь для обоих графиков можно задавать поисковые запросы, чтобы исключить или добавить в результат задачи, свимлэйны или подзадачи. Например, чтобы построить график только из подзадач, исключив свимлэйны, введите в строку запроса has:
Также можно настроить график по количеству задач, по оценке времени или по внесенному времени (если в проекте используется трекинг времени).
Теперь при создании новой доски можно выбрать один из трех доступных шаблонов: Scrum, Kanban, или шаблон для настройки доски вручную. Параметры по умолчанию отличаются для каждого типа, например, для Scrum доски будет задано наличие свимлэйнов, карточек, колонок и так далее.
Мы также добавили предзаполненные настройки для нового проекта. При создании можно выбрать стандартный проект трекинга задач, Scrum или Kanban, которые содержат готовый набор полей и воркфлоу, согласно выбранной методологии. Все настройки можно изменить в любое время для более полного соответствия вашему рабочему процессу.
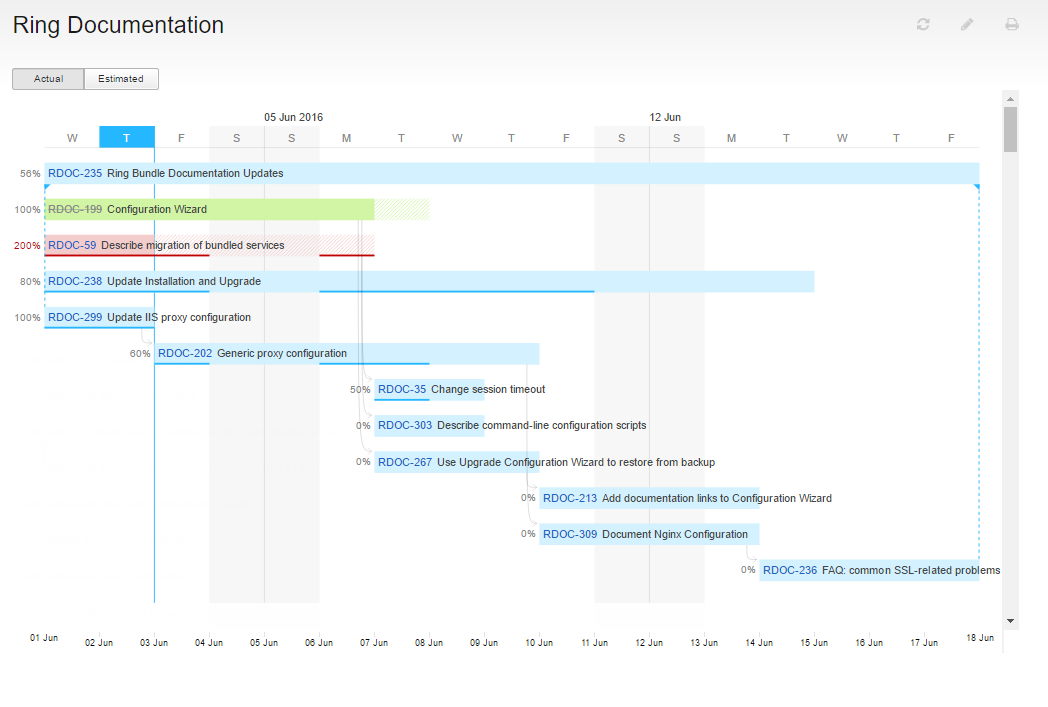
Диаграмма Ганта — одна из самых ожидаемых пользователями новинок. Она помогает планировать, что и когда будет сделано, иллюстрирует зависимость задач друг от друга, а также показывает текущий прогресс. График строится на основе поискового запроса и может включать задачи из нескольких проектов. С помощью диаграммы Ганта можно рассчитать, сколько времени требуется на выполнение задач в зависимости от того, сколько сотрудников работают над ними, и предугадать, сколько ресурсов необходимо добавить, чтобы выполнить задачи быстрее.
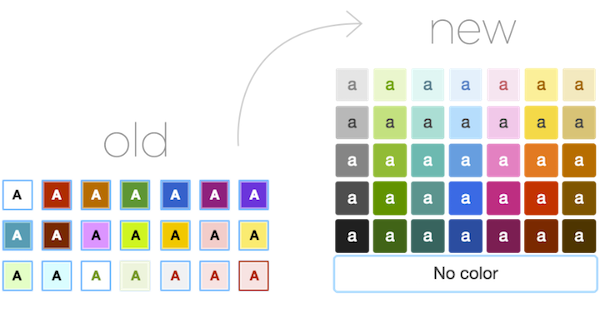
В YouTrack 7.0 мы улучшили цветовую палитру — теперь она состоит из основных цветов и их оттенков. Обратите внимание, что цвета полей, которые заданы в YouTrack по умолчанию, были также изменены. В настройках проекта вы можете скорректировать цвета в любое время.
Теперь можно добавлять значения полей откуда угодно — с доски, со списка задач, из бэклога. Эта функциональность доступна администратору и значительно ускоряет настройку проекта.
Вы можете создавать нескольких панелей мониторинга (dashboards), а также делиться ими с командой. Также можно контролировать права на редактирование, разрешив или ограничив группе пользователей доступ к вашей панели.
Теперь YouTrack поддерживает SAML 2.0, т. е. можно использовать свой логин от YouTrack при входе в другие сервисы, например Zendesk или Google Apps for Work.
— Улучшенный раздел управления правами доступамиВ обновленном интерфейсе раздел управление правами доступа разбит на приложения: YouTrack и Hub. Вы можете видеть, какие права связаны с управлением задачами в YouTrack, а какие — с административной частью Hub.
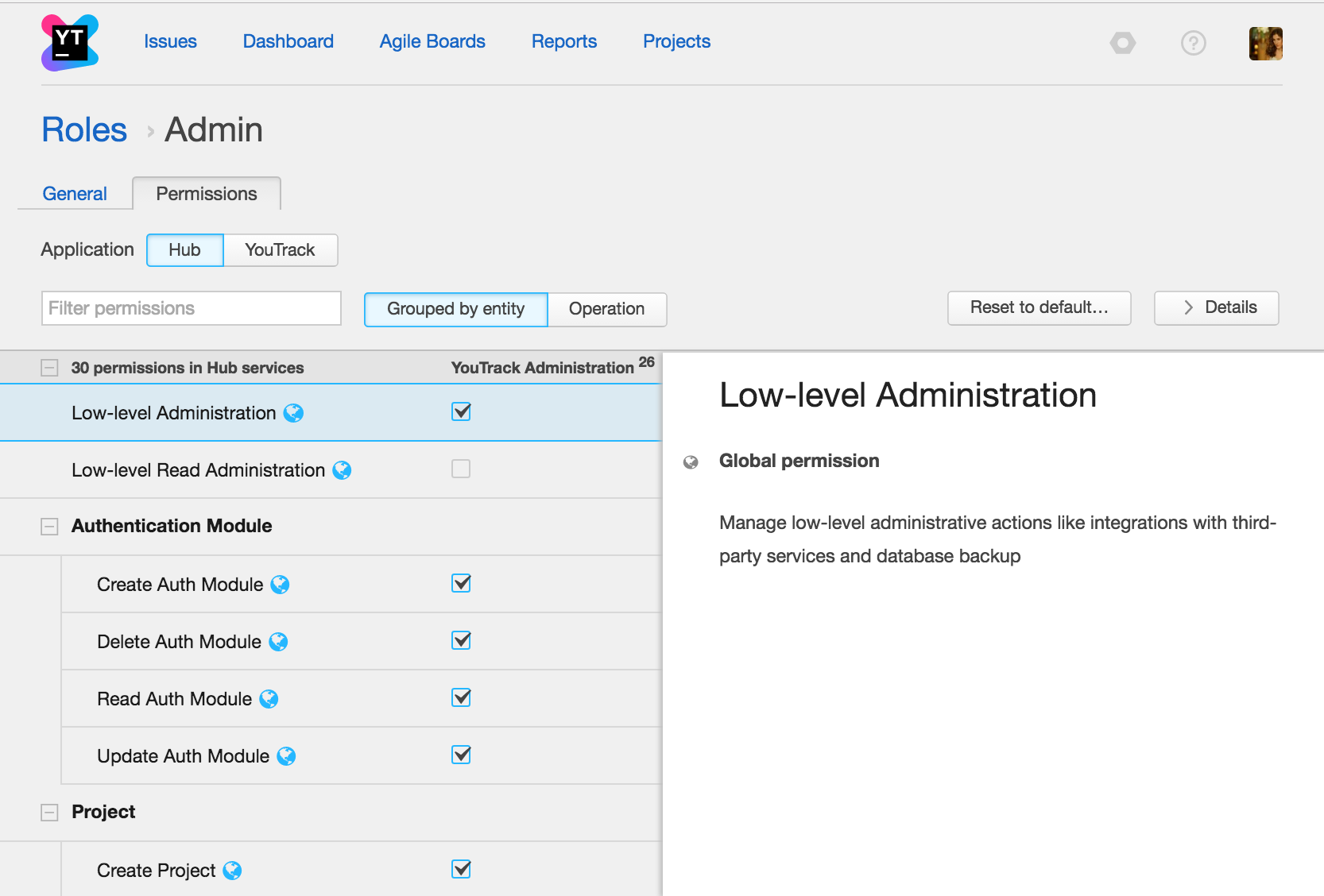
Администратор проекта теперь может установить уровень надежности паролей, чтобы повысить безопасность сервера и защитить систему от атак. Это значит, что определенные требования будут применены к паролям всех ваших пользователей.
— Удаление профиля пользователяТеперь пользователи могут самостоятельно удалить свой профиль из YouTrack. Администраторы также могут использовать эту функцию для удаления устаревших и неиспользуемых профилей пользователей.
— Предварительный просмотр ссылок в Slack, Facebook, TelegramНапоследок — небольшая, но очень полезная функция. Когда вы делитесь ссылкой на задачу в Slack, Facebook или Telegram, она будет автоматически открываться для предпросмотра. Стоит отметить, что данная опция доступна только для публичных задач.
Мы также сняли небольшой ролик (на английском языке), чтобы наглядно показать основные нововведения:
Будем рады, если вы попробуете YouTrack 7.0 и поделитесь впечатлениями. Можно скачать бесплатную версию для 10 пользователей или зарегистрироваться в облаке, чтобы воспользоваться пробной версией на 30 дней.
Если вы уже используете облачный YouTrack, то ваш инстанс будет переведен на новую версию в течение месяца. Сервера обновляются каждый понедельник, так что ждать осталось совсем недолго. Если же вам не терпится перейти на YouTrack 7.0, напишите нашей команде техподдержки, и мы включим вас в ближайшее обновление.
Кстати, 26 октября мы будем проводить бесплатный вебинар, на котором расскажем о нововведениях более подробно, а также поделимся лучшими практиками использования Agile доски. Зарегистрироваться можно тут .
Ваша команда Jetbrains YouTrack
The Drive to Develop
Среда, 24 Августа 2016 г. 15:51 (ссылка )
Всем привет, пока переводится статья про релиз ГитЛаба 8.11. решил опубликовать перевод еще одной полезной статьи:
В зависимости от рабочих задач и потребностей клиентов разработчикам приходится использовать разные платформы управления репозиториями. Типичный разработчик участвует в каком-нибудь открытом проекте на GitHub, а на работе хостит проект одного клиента на GitLab, а другого — в Mercurial и на Bitbucket. Переключения между платформами осложняются тем, что в них одни и те же вещи могут называться совершенно по-разному. В этой статье мы поможем вам сопоставить различия и заодно объясним, почему мы выбрали именно такие названия.
Начиная с версии 8.4 в GitLab значительно улучшился процесс миграции репозиториев из GitHub. Теперь GitLab импортирует не только репозитории, но ещё и вики-страницы, тикеты и пулл-реквесты. При этом большинство сущностей не меняют своего названия. Например, специфические термины Git, такие как commit или push, везде одинаковы. Не меняются и такие общие термины, как users, webhooks и issues.
Но некоторые термины всё-таки отличаются. Например, то, что в GitHub и Bitbucket называется пулл-реквестом (pull-request), мы называем мерж-реквестом (merge-request). Мы так его назвали, потому что это запрос на merge ветки для выделенной функциональности (feature branch) с мастер-веткой; собственно команда pull там нигде не применяется. К слову, в Git есть отдельная команда request-pull. она тоже позволяет предложить свои изменения и использует-таки команду pull. но имеет совсем другой механизм .
Если вы только начинаете работать с GitLab, эта таблица поможет вам быстрее освоиться:
В GitLab все репозитории принадлежат группам. В группе можно настроить уровни доступа к репозиторию и оповещения для различных пользователей
Команды, Репозитории и ОрганизацииДавайте разберёмся, чем отличаются команда (team), репозиторий (repository) и организация (organization). В GitHub репозитории содержат собственно репозиторий Git или SVN, а также тикеты (issues), статистику участия и т.п. При этом, пользователи нередко называют репозитории проектами.
В GitLab мы устранили неоднозначность, явно называя такую структуру проектом (project). Проект включает в себя репозиторий Git, тикеты, мерж-реквесты и всё остальное. На странице конфигурации проекта можно:
Важно понимать, что даже если вы импортируете в GitLab только чистый репозиторий Git или нечто, что в источнике называется «репозиторием», в результате вы всегда получите проект GitLab.
Важное отличие: в Bitbucket проектом (project) называется объединение нескольких репозиториев. Такие проекты в свою очередь принадлежат командам (teams). В GitHub аналогичную задачу выполняют организации (organizations).
В GitLab такие структуры, объединяющие несколько проектов, называются группами (groups). Пользователи, входящие в группу, получают доступ на чтение, изменение и настройку проектов в зависимости от своей роли в группе. Каждый проект принадлежит только одной группе, но его можно «расшарить» для других групп. Эта фича есть в Gitlab Enterprise Edition, а также в GitLab Community Edition начиная с версии 8.5. Если вы хотите явным образом запретить расшаривание проектов, это можно сделать в настройках группы.
Надеюсь, что эта статья помогла вам лучше разобраться в терминологии. Если у вас ещё остались вопросы, задавайте их в комментариях.
Немного историиВ самом начале 2010 года Vincent Driessen пишет отличную статью A successful Git branching model. Для понимания того, о чем пойдет речь дальше, со статьей нужно, конечно же, познакомиться. А для тех, кому сложен язык оригинальной статьи, на хабре есть её отличный перевод .
С этого момента описанная модель ветвления GitFlow . начинает, что называется, расходиться по миру. Её берут на вооружение многие команды. Авторы пишут много статей об успешном её использовании. Она получает поддержку в большинстве инструментов, которые используют разработчики:

Кажется, что модель идеальна. Быть может так оно и есть, если у вас небольшая команда, неизменяемый скоуп релизов, высокая культура работы с VCS. Тогда, действительно, GitFlow может и удовлетворит все ваши потребности. Но, к сожалению, описанные условия подходят не всем командам и не всем проектам. К слову, найти статьи, в которых бы авторы описывали проблемы этой модели не так уж и просто даже в 2016 году. Но как мы все знаем, серебряной пули нет. а, значит, и в этой модели всё хорошо далеко не для всех.
Что не так с классическим GitFlow ?История начинается с того, что классический GitFlow предполагает большое число merge -коммитов. Причем проблема не в самих merge -коммитах (которые, как вы дальше увидите, всё равно будут присутствовать в истории), а в их огромном количестве. Дебаты на тему «Merge vs Rebase » часто встречаются на просторах интернета (поисковики подскажут). У Atlassian, кстати, есть хорошая статья. в которой описывается разница этих двух подходов. Так в чем же дело?
История коммитов становится просто ужасной. На фото ниже всего один день работы команды.

Да, у нас есть git log --first-parent и другие возможности отфильтровать дерево, но это несильно помогает полноценному анализу истории. Если же у команды разработчиков, кроме классического GitFlow. нет никаких других соглашений по ведению Git -репозитория, то в этой истории можно будет целыми пачками наблюдать коммиты c абсолютно бессмысленными сообщениями "fix ", "refactoring ", "". и т.д. Это сделает историю коммитов практически непригодной даже для самого поверхностного анализа.
Если ваш релизный скоуп меняется (а в Agile это бывает не редко), то классический GitFlow вам вряд ли подойдет. Если в вашем рабочем процессе часто встречаются фразы, попадающие под шаблон "Заказчику срочно нужна сборка, в которой [\w]* ", то с историей коммитов, наглядно представленной в предыдущем пункте, ваша жизнь превратится в сущий ад. Я не шучу.
А что хотелось бы?Очень сложно объяснить, почему так важно, чтобы история коммитов была чистой. Опытным разработчикам не требуется объяснения, почему чистым должен быть исходный код, для них это утверждение — аксиома. На мой взгляд аналогия тут абсолютно прямая. Также как и каждая строчка чистого кода, каждый коммит истории должен быть на своем месте и понятен любому, даже стороннему, разработчику. Да, грязный код тоже может быть рабочим, но на сколько удобно с ним работать? Как быстро удастся в нем разобраться новому сотруднику? То же самое и с историей коммитов. Даже грязная история будет знать абсолютно всё обо всех изменениях в проекте, но удобно ли будет с ней работать?
Для того чтобы работа с Git -репозиторием была простой, удобной и понятной, на мой взгляд необходимы всего две вещи:
Линейность истории изменений. Это свойство ограничивает толщину дерева коммитов константой, делая его максимально простым и наглядным для анализа.
Если оба свойства выполняются, дерево коммитов будет выглядеть следующим образом:

Нужно совсем не много подредактировать классический GitFlow. При этом работа с develop. master. release и hotfix бранчами остаётся ровно такой же, как и в классическом GitFlow. Правки же коснутся исключительно работы с feature -бранчами.
Перед вливанием feature -бранча в итоговый, ему необходимо сделать интерактивный rebase командой git rebase -i develop. при этом все промежуточные коммиты в бранче слить (squash 'ить) в один. Бывают случаи, когда историю коммитов в feature -бранче имеет смысл оставить, но эти случаи на практике очень редки. При хорошей декомпозиции задач каждая небольшая задача представляет собой атомарное и логически завершенное изменение системы, которое отлично укладывается в одном коммите. Учитывая, что все изменения в рамках задачи можно соединить в один коммит в самый последний момент, во время работы над задачей разработчик может по-прежнему беспрепятственно создавать множество промежуточных коммитов, необходимых ему для потенциального отката. Ну и не лишним будет добавить, что есть отличная команда rerere . помогающая разработчикам, часто выполняющим операцию rebase .
Заливать feature -бранч в удалённый репозиторий необходимо с помощью команды git push --force. так как в предыдущем пункте мы произвели rebase -бранча.
Как видите, изменений по работе с репозиторием совсем не много. И, подводя некий итог этой части статьи, хочу поделиться ссылкой на отличную статью, где также рассматриваются плюсы и минусы классического GitFlow и Rebase Flow .
Поддержка Rebase Flow в менеджерах репозиториевКак я уже упоминал в самом начале статьи, поддержка классического GitFlow есть во множестве инструментов, в том числе и в различных менеджерах репозиториев. Поэтому дальше я рассмотрю вопрос о том, как сейчас обстоят дела с поддержкой Rebase Flow в популярных менеджерах репозиториев. При этом моя оценка будет в формате обычной университетской отметки.
Поддержка Rebase Flow. ХОРОШО
На самом деле, у GitHub есть практически всё что нужно. В настройках репозитория есть галочка «Allow squash merging».
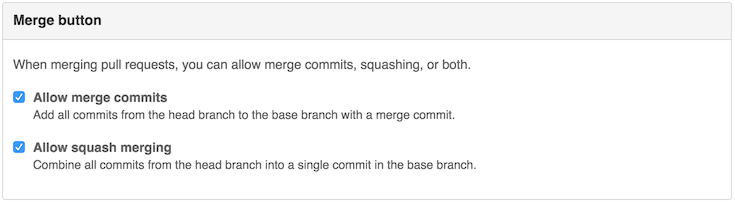
Она позволяет при мерже pull request 'а выбрать соответствующий пункт и отредактировать итоговое сообщение к коммиту

В результате pull request будет смержен линейно и все коммиты будут схлопнуты в один.
Единственный минус, который я вижу на стороне GitHub, это
Всё вышесказанное относится и к GitHub Enterprise. который может быть развернут на серверах вашей компании.
Поддержка Rebase Flow. НЕУДОВЛЕТВОРИТЕЛЬНО
А по факту её просто нет. Если вы хотите использовать в своей работе Rebase Flow. то BitBucket в этом вам никак не поможет, всё придётся делать самостоятельно.
И это удивительно, учитывая что по тексту этой статьи я не раз ссылался на отличные статьи с сайта Atlassian. Будем надеяться, что в будущем ситуация с поддержкой Rebase Flow изменится, тем более что задачи на это уже давно заведены
Давайте теперь посмотрим, что с поддержкой Rebase Flow у платного продукта от Atlassian.
Atlassian BitBucket Server (a.k.a. Atlassian Stash)Поддержка Rebase Flow. УДОВЛЕТВОРИТЕЛЬНО
Я рассматриваю BitBucket v4.5.2 и, возможно, в будущих версиях ситуация изменится в лучшую сторону. Сейчас же с поддержкой в BitBucket Server несколько лучше, чем в его облачном брате. Если у вас есть доступ к администраторам, то вы можете их любезно попросить в файле bitbucket.properties поменять для вашего проекта/репозитория настройки мержа pull request 'ов (документация )
Значения настроек могут быть следующими
Как вы видите, настройки достаточно гибкие, но есть две проблемы
Как только эти две проблемы будут устранены, поддержку Rebase Flow у BitBucket можно будет оценить на отлично. А пока.
Поддержка Rebase Flow. ХОРОШО
Оценивая поддержку на https://gitlab.com. мы, по сути, оцениваем поддержку в продукте GitLab EE. на базе которого он реализован. Что же касается поддержки Rebase Flow в GitLab CE. то её там попросту нет.
Для понимания того, как именно организована поддержка Rebase Flow. взглянем на настройки проекта

Как вы видите, тут даже есть промежуточный вариант полулинейной истории, когда merge -коммиты остаются, но возможность принять pull request появляется только в том случае, если feature -бранч является линейным продолжением. Если выбран этот вариант с полулинейной историей или «Fast-forward merge», у нас появляется дополнительная возможность управления pull request 'ом. А именно появляется кнопка «Rebase onto. », позволяющая сделать из feature -бранча линейное продолжение истории.
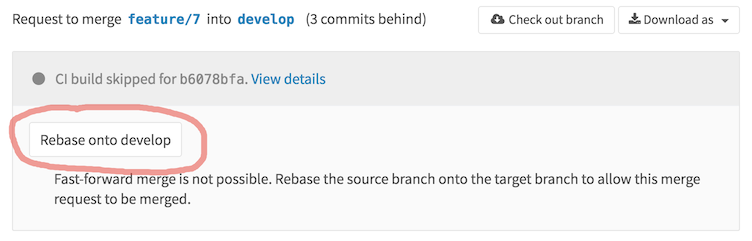
После чего можно без проблем принять pull request. который будет смержен без создания отдельного merge -коммита.

Более подробное описание этой функциональности можно посмотреть в документации (раз. два ). Несмотря на то, что скриншоты в ней немного устарели, она не потеряла своей актуальности. На этом в принципе поддержка Rebase Flow заканчивается. То что она вообще есть — это, конечно, плюс, но в ней явно не хватает
Сейчас большинство менеджеров Git -репозиториев реализуют поддержку Rebase Flow в каком-то виде. И удобство работы в них сейчас на порядок выше, чем несколько лет назад. Но всё-таки, на мой взгляд, минусы пока есть у всех продуктов, и я продолжаю верить, что в будущем они их исправят.
[Перевод] Монолитные репозитории в GitПонедельник, 28 Марта 2016 г. 17:41 (ссылка )
Многие выбрали Git за его гибкость: в частности, модель веток и слияний позволяют эффективно децентрализовать разработку. В большинстве случаев эта гибкость является плюсом, однако некоторые сценарии поддержаны не так элегантно. Один из них — это использование Git для больших монолитных репозиториев — монорепозиториев. Эта статья исследует проблемы монорепозиториев в Git и предлагает способы их смягчения.

Скала Улуру в Австралии как пример монолита — КДПВ, не более
Что такое монорепозиторий?Определения разнятся, но мы будем считать репозиторий монолитным при выполнении следующих условий:
Мне видится пара возможных сценариев:
При таких условиях предпочтение может быть отдано единому репозиторию, поскольку он позволяет гораздо проще делать большие изменения и рефакторинги (к примеру, обновить все микросервисы до конкретной версии библиотеки).
С тысячами коммитов в неделю и сотнями тысяч файлов, главный репозиторий исходного когда Facebook громаден — во много раз больше,
чем даже ядро Linux, в котором, по состоянию на 2013 год, находилось 17 миллионов строк кода в 44 тысячах файлов.
При проведении тестов производительности в Facebook использовали тестовый репозиторий со следующими параметрами:
С хранением несвязанных проектов в монорепозитории Git возникает много концептуальных проблем.
Во-первых, Git учитывает состояние всего дерева в каждом сделанном коммите. Это нормально для одного или нескольких связанных проектов, но становится неуклюжим для репозитория со многими несвязанными проектами. Проще говоря, на поддерево, существенное для разработчика, влияют коммиты в несвязанных частях дерева. Эта проблема ярко проявляется с большим числом коммитов в истории дерева. Поскольку верхушка ветки всё время меняется, для отправки изменений требуется частый merge или rebase .
Тег в Git — это именованный указатель на определённый коммит, который, в свою очередь, ссылается на целое дерево. Однако польза тегов уменьшается в контексте монорепозитория. Посудите сами: если вы работаете над веб-приложением, которое постоянно развёртывается из монорепозитория (Continuous Deployment), какое отношение релизный тег будет иметь к версионированному клиенту под iOS?
Проблемы с производительностьюНаряду с этими концептуальными проблемами существует целый ряд аспектов производительности, влияющих на монорепозиторий.
Количество коммитовХранение несвязанных проектов в едином большом репозитории может оказаться хлопотным на уровне коммитов. С течением времени такая стратегия может привести к большому числу коммитов и значительному темпу роста (из описания Facebook — "тысячи коммитов в неделю" ). Это становится особенно накладно, поскольку Git использует направленный ациклический граф (directed acyclic grap — DAG) для хранения истории проекта. При большом числе коммитов любая команда, обходящая граф. становится медленнее с ростом истории.
Примерами таких команд являются git log (изучение истории репозитория) и git blame (аннотирование изменений файла). При выполнении последней команды Git придётся обойти кучу коммитов, не имеющих отношение к исследуемому файлу, чтобы вычислить информацию о его изменениях. Кроме того, усложняется разрешение любых вопросов достижимости: например, достижим ли коммит A из коммита B. Добавьте сюда множество несвязанных модулей, находящихся в репозитории, и проблемы производительности усугубятся.
Количество указателей (refs )Большое число указателей — веток и тегов — в вашем монорепозитории влияют на производительность несколькми путями.
Анонсирование указателей содержит каждый указатель вашего монорепозитория. Поскольку анонсирование указателей — это первая фаза любой удалённой Git операции, под удар попадают такие команды как git clone. git fetch или git push. При большом количестве указателей их производительность будет проседать. Увидеть анонсирование указателей можно с помощью команды git ls-remote. передав ей в качестве аргумента URL репозитория. Например, такая команда выведет список всех указателей в репозитории ядра Linux:
Если указатели хранятся не в сжатом виде, перечисление веток будет работать медленно. После выполнения команды git gc указатели будут упакованы в единый файл, и тогда перечисление даже 20.000 указателей станет быстрым (около 0.06 секунды).
Любая операция, которая требует обхода истории коммитов репозитория и учитывает каждый указатель (например, git branch --contains SHA1 ) в монорепозитории будет работать медленно. К примеру, при 21.708 указателях поиск указателя, содержащего старый коммит (который достижим из почти всех указателей), занял на моём компьютере 146.44 секунды (время может отличаться в зависимости от настроек кеширования и параметров носителя информации, на котором хранится репозиторий).
Количество учитываемых файловИндекс ( .git/index ) учитывает каждый файл в вашем репозитории. Git использует индекс для определения, изменился ли файл, выполняя stat(1) для каждого файла и сравнивая информацию об изменении файла с информацией, содержащейся в индексе.
Поэтому количество файлов в репозитории оказывает влияние на производительность многих операций:
Эти эффекты могут варьироваться в зависимости от настроек кешей и характеристик диска, а заметными становятся только при действительно большом количестве файлов, исчисляемом в десятках и сотнях тысяч штук.
Большие файлыБольшие файлы в одном поддереве/проекте влияют на производительность всего репозитория. Например, большие медиа-файлы, добавленные в проект iOS-клиента в монорепозитории, будут клонироваться даже разработчикам, работающим над совершенно другими проектами.
Комбинированные эффектыКоличество и размер файлов в сочетании с частотой их изменений наносят ещё больший удар по производительности:
Как следствие описанных эффектов, монолитные репозитории — это испытание для любой системы управления Git-репозиториями, и Bitbucket не является ислючением. Ещё важнее то, что порождаемые монорепозиториями проблемы требуют решения как на стороне сервера, так и клиента.
Влияние на сервер
git add для больших файлов, git push и git gc работают медленно
Стратегии смягчения последствийКонечно, было бы здорово, если бы Git специально поддержал вариант использования с монолитными репозиториями. Хорошая новость для подавляющего большинства пользователей заключается в том, что на самом деле, действительно большие монолитные репозитории — это скорее исключение, чем правило, поэтому даже если эта статья оказалась интересной (на что хочется надеяться), она вряд ли относится к тем ситуациям, с которыми вы сталкивались.
Есть целый ряд методов снижения вышеописанных негативных эффектов, которые могут помочь в работе с большими репозиториями. Для репозиториев с большой историей или большими бинарными файлами мой коллега Никола Паолуччи описал несколько обходных путей.
Удалите указателиЕсли количество указателей в вашем репозитории исчисляется десятками тысяч, вам стоит попробовать удалить те указатели, которые стали ненужными. Граф коммитов сохраняет историю эволюции изменений, и поскольку коммиты слияния содержат ссылки на всех своих родителей, работу, которая велась в ветках, можно отследить даже если сами эти ветки уже не существуют. К тому же, коммит слияния зачастую содержит название ветки, что позволит восстановить эту информацию, если понадобится.
В процессе разработки, основанном на ветках. количество долгоживущих веток, которые следует сохранять, должно быть небольшим. Не бойтесь удалять кратковременные feature-ветки после того, как слили их в основную ветку. Рассмотрите возможность удаления всех веток, которые уже слиты в основную ветку (например, в master или production ).
Обращение с большим количеством файловЕсли в вашем репозитории много файлов (их число достигает десятков и сотен тысяч штук), поможет быстрый локальный диск и достаточный объём памяти, которая может быть использована для кеширования. Эта область потребует более значительных изменений на клиентской стороне, подобных тем, которые Facebook реализовал для Mercurial .
Их подход заключается в использовании событий файловой системы для отслеживания изменённых файлов вместо итерирования по всем файлам в поисках таковых. Подобное решение, также с использованием демона, мониторящего файловую систему, обсуждалось и для Git. однако на данный момент так и не привело к результату.
Используйте Git LFS (Large File Storage — хранилище для больших файлов)Для проектов, которые содержат большие файлы, например, видео или графику, Git LFS является одним из способов уменьшения их влияния на размер и общую производительность репозитория. Вместо того, чтобы хранить большие объекты в самом репозитории, Git LFS под тем же имененм хранит маленький файл-указатель на этот объект. Сам объект хранится в специальном хранилище больших файлов. Git LFS встраивается в операции push. pull. checkout и fetch. чтобы прозрачно обеспечить передачу и подстановку этих объектов в рабочую копию. Это означает, что вы можете работать с большими файлами так же, как обычно, при этом не раздувая ваш репозиторий.
Bitbucket Server 4.3 полностью поддерживает Git LFS v1.0+. а кроме того, позволяет просматривать и сравнивать большие графические файлы, хранящиеся в LFS.
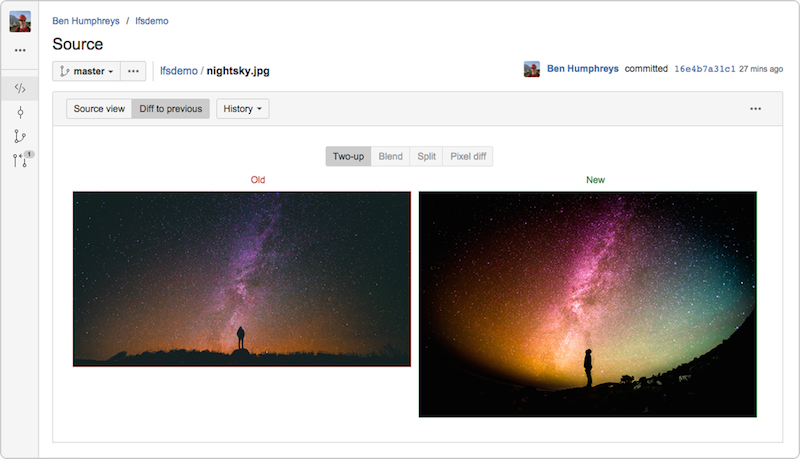
Мой коллега Стив Стритинг активно участвует в разработке проекта LFS и не так давно написал о нём статью .
Определите границы и разделите ваш репозиторийНаиболее радикальное решение — это разделение монорепозитория на меньшие, более сфокусированные репозитории. Попробуйте не отслеживать каждое изменения в едином репозитории, а идентифицировать границы компонентов, например, выделяя модули или компоненты, имеющие общий цикл выпуска версий. Хорошим признаком компонентов может быть использование тегов в репозитории и то, насколько они имеют смысл для других частей дерева исходного кода.
Хоть концепт монорепозитория и расходится с решениями, сделавшими Git чрезвычайно успешным и популярным, это не означает, что ст'oит отказываться от возможностей Git только потому, что ваш репозиторий монолитный: в большинстве случаев, для возникающих проблем есть работающие решения.
Штефан Заазен — архитектор Atlassian Bitbucket. Страсть к DVCS привела его к миграции команды Confluence с Subversion на Git и, в конечном итоге, к главной роли в разработке того, что сейчас известно под названием Bitbucket Server. Штефана можно найти в Twitter под псевдонимом @stefansaasen .
Поиск кода в Bitbucket ServerПятница, 25 Марта 2016 г. 09:35 (ссылка )
С удовольствием делюсь новостью, которая, надеюсь, порадует некоторых читателей Хабра: в Bitbucket Server вот-вот появится возможность поиска по коду. Буквально на днях вышел релиз по программе раннего доступа (EAP).
Начну с вольного перевода обращения менеджера продукта, опубликованного в блоге Atlassian :
Как часто это случалось с вами: вы видите сообщение об ошибке, но не знаете, в какой части кода она происходит, или вам известно название функции, но не репозиторий, в коде которого она определена. Многие из вас просили добавить в Bitbucket Server поиск по коду, и я рад сообщить, что ваше ожидание подошло к концу. Сегодня мы приглашаем наших пользователей опробовать поиск по коду в Bitbucket Server через программу раннего доступа (EAP). Теперь вы можете искать и находить нужный код с помощью строки поиска:

Мы понимаем, что у многих команд огромное количество кода. Поэтому мы сделали так, чтобы можно было легко ограничить результаты поиска конкретным проектом или репозиторием с помощью поисковых фильтров. Кроме того, можно искать код на заданном языке (например, lang:java ) или в файлах с определённым расширением (например, ext:css ).

Операторы AND. OR и NOT помогут уточнить запрос, они полезны для дальнейшей фильтрации результатов поиска в случае, когда их слишком много.

Рад, что вы спросили! Здесь вы можете скачать дистрибутив Bitbucket Server EAP с поддержкой поиска по коду, а с запуском и настройкой должна помочь подготовленная нами пошаговая инструкция. Мы будем признательны, если вы расскажете о своих впечатлениях от EAP дистрибутива, — ваши отзывы крайне важны для нас. Заполнив эту короткую и простую анкету. вы поможете нам улучшить поиск для вас и других пользователей Bitbucket к его официальному релизу.
Мы работаем над тем, чтобы в скором времени порадовать вас б'oльшими возможностями. Удачного поиска!
TL;DRВ кратком пересказе, инструкция по установке сводится к следующим шагам:
Как можно было заметить по страницам справки и содержимому дистрибутива, для хранения индекса, с помощью которого осуществляетя поиск, используется Elasticsearch. Он, в свою очередь, основан на известной библиотеке Apache Lucene .

В Bitbucket Server поиск обеспечивают два модуля: первый занимается индексацией репозиториев, второй обслуживает поисковые запросы от пользователей. Индексация происходит постоянно в фоновом режиме. Если вы обновляете Bitbucket Server, который уже содержит какое-то количество репозиториев, первоначальная индексация может занять некоторое время, однако как только она завершится, последующие изменения обрабатываются очень быстро. Стоит отметить, что поиск доступен сразу, но пока идёт индексация, его результаты могут быть неполными. Кроме того, с целью оптимизации производительности введена небольшая задержка между моментом изменения репозитория (например, коммит нового кода) и моментом, когда это изменение отражается в результатах поиска. По умолчанию, эта задержка может достигать 15 секунд.
Процедура установки, по сравнению с предыдущими версиями Bitbucket Server, не изменилась: все конфигурационные действия, необходимые для работы поиска, выполняются автоматически. В то же время, необязательно использовать встроенный экземпляр Elasticsearch: при желании, можно настроить требуемую конфигурацию самостоятельно.
Что именно можно искать?Поиск имеет ряд ограничений:
Поисковый запрос должен содержать, по крайней мере, один терм, который может быть словом или заключённой в кавычки фразой.
ОператорыОператоры могут быть добавлены в запрос, чтобы уточнить поиск. Вот их текущий список:
Соответствует файлам, содержащим слово "bitbucket" и любое из слов "server" или "cloud"
Запрос может содержать несколько термов, и по умолчанию, они неявно объединяются с помощью логического оператора AND. То есть, запрос bitbucket server эквивалентен запросу bitbucket AND server .
МодификаторыМодификаторы помогают ограничить область поиска. Они записываются в формате модификатор:значение. Если в запросе содержится несколько модификаторов, они неявно объединяются с помощью оператора AND и применяются ко всему выражению. На данный момент поддержаны следующие модификаторы:
Поиск может быть ограничен языками и расширениями файлов. Для некоторых языков эти два критерия идентичны: например, модификаторы lang:clojure и ext:clj приведут к одинаковому результату. Однако есть и такие языки, которым соответствуют несколько расширений файлов: например, расширения .hs и .lhs используются в Haskell, и файлы с любым из этих расширений будут включены в результаты поиска с модификатором lang:haskell .
На всякий случай, замечу, что инструкции на приведённых страницах справки в ближайшее время будут дорабатываться, чтобы сделать процедуры установки, настройки и использования поиска в Bitbucket Server ещё лучше. Напомню, ваши комментарии касательно любых аспектов использования EAP релиза горячо приветствуются .
Для меня эта новость особенно приятна и важна потому, что я принимаю непосредственное участие в разработке поиска. Буду рад ответить на любые вопросы и комментарии.
Пятница, 06 Ноября 2015 г. 15:30 (ссылка )
В предыдущей публикации я описывал список продуктов и их настройки, которые необходимы для работы нашей организации.
В этой статье я постараюсь описать как мы это всё используем в ежедневной работе всего коллектива разработки.
На протяжении 4х лет у нас выработался следующий формат команды разработки:
В итоге команда размером около 10-11 человек. Таких команд (ячеек) у нас несколько.
Работа в основном в стиле стартапа, когда нет конкретной и подробной постановки. Очень часто эксперименты вроде “а давайте попробуем так, посмотрим что получится” или “вы классно все сделали, но теперь надо все совсем по-другому”.
За эти годы концепцию нашей работы можно описать одной фразой — это “стремительная смена концепции”.
Понятное дело, что применить в таких условиях различные методологии никак не удавалось.
Начинал в этой системе я как программист, потом Team lead, ну а теперь PM (DM). Т.е. руковожу, полностью участвую в проектировании и иногда даже пописываю. Во времена моего программирования у меня был замечательный ПМ (выходец из тестировщиков), которая поддерживала все мои идеи по автоматизации workflow. Даже более того, концептуально этот процесс придуман ей, а я уже смог его технически реализовать и в некоторых местах усовершенствовать.
Перейдем к сути.Как мы работали ранее с использованием только Jira и SVN:
После сложного пути проб и ошибок, спустя 3 года мы пришли к следующему процессу.

Все задачи появляются у нас либо после совещания с высшим руководством, либо пожелания от заказчика, либо придумываем что-то сами (или находим баги).
В случаях, когда задача не односложная, собирается мини-совещание из ПМ, тимлида, QA-лида и аналитика. После обсуждения и придумывания, что и как будем разрабатывать, обычно сразу дробим это на логически завершенные небольшие задачки (не дольше работы 1го дня программиста) и грубо прикидываем сроки на реализацию (для планов для высшего руководства).
Аналитик садится и вдумчиво излагает постановку в Confluence. После этого данную постановку согласовывает с ПМ, а тот при необходимости с высшим руководством.
Затем на основании этой постановки создается задача в Jira.
Часто задачи сразу появляются в Jira минуя этап с Confluence.
Любая задача, которая появляется в Jira сразу попадает на шаг “Постановка задачи”. На данном этапе заполняются такие данные как:
На этапе постановки задача находится у ее автора и на нее больше никто не смотрит и о ней не знает.
Как только автор окончательно формулирует постановку задачи, он ее толкает на следующий (единственно возможный) шаг в workflow — ревизия постановки.
Ревизия постановкиПри переходе на этот шаг триггеры Jira автоматом меняют ответственного задачи на ПМ-а.
Этот шаг предназначен для того, чтобы ПМ перечитал описание задачи и убедился, что автор правильно понял постановку и корректно описал задание для программиста. Очень часто из-за недостаточного взаимопонимания задача делается и тестируется до самого конца и только уже при релизе видно, что сделали совсем не то, что изначально требовалось.
Так же на этом шаге ПМ принимает решение нужно ли реализовывать вообще данную задачу. Или нужно ли ее реализовывать именно в эту версию.
На этом этапе есть два варианта workflow: вернуть назад на постановку (доработку описания) или продвинуть дальше в работу.
Так же я часто на этом шаге назначаю ответственного тимлида для того чтобы он сам определил исполнителя
Ожидание работ
При выборе этого шага я настроил экран, в котором надо задавать исполнителя, поле “Программист” и планируемое время.
Этот шаг — пул задач программиста, который надо выполнить за версию в порядке, указанном в поле приоритет или в порядке любом удобном, если приоритет одинаковый.
Так уж получается, что во время работы над версией частенько этот список пополняется.
В работеНажимая на кнопку “В работу”, задача переходит в состояние “В работе” и благодаря плагину “Automated Log Work for JIRA” автоматически запускается счетчик логирования времени, который останавливается и сохраняет набежавшее значение при переводе задачи в другие статусы. На этом шаге программист может:
Чтобы работала связка FishEye+Crucible+Bitbucket+Jira, при комите программист обязательно в коменте должен указать номер задачи (PRJ-343).
У нас в команде договоренность, что мелкие правки типа подвинуть кнопку правее или раскрасить зелёный зеленее, можно сразу бросать на сборку. Иначе — ОБЯЗАТЕЛЬНО на ревизию кода.
И так, бросаем задачу на ревизию кода, и при этом ответственным назначаем тимлида.
Ревизия кодаНа этом шаге тимлид в специальной секции Development в Jira смотрит какой именно комит был сделан программистом и нажимает специальную кнопку “Code Review”.

После нажатия автоматически открывается Crucible и создается ревью на указанный комит (или несколько комитов).
Тимлид может видеть дерево файлов, которые правил программист ну и соответственно диференсы. Может оставить комментарий к любой строке кода или общий к ревизии. Crucible позволяет даже указать степень критичности проезда программиста.
После мук изучения чужого гуанокода, тимлид либо проталкивает задачу на шаг сборки, либо возвращает программисту в ожидание работ.
Программист в этом случае в секции Development видит Code Review и его статус. При переходе на этот Code Review опять же открывается Crucible, где программист может наглядно увидеть, где именно он налажал.
При переводе на шаг “Ожидание сборки”, тимлид выбирает ответственным тестировщика, который указан в спец поле, либо если оно не заполнено, то QA-лида.
Ожидание сборкиТак как сервер тестирования у нас один общий, то сборка по расписанию не годится. Нельзя подменять сайт во время его тестирования.
Поэтому, обычно у нас тестировщики договариваются и, если никто не против, собирают себе свежую версию ресурса.
Делают они это с помощью Jenkins. В нем созданы по три сборки на каждый проект: сборка для тестов, сборка для разработки, сборка БД.
В сборке исходников настроен следующий алгоритм:
В сборках БД все тоже самое, только вместо шага 3 выполняется следующее с помощью ssh команд на сервере:
3.1. Отрубить все коннекты к БД.
3.3. Восстановить БД прошлой версии.
3.4. Прокрутить на ней все скрипты новой версии.
БД у нас собирают крайне редко, только когда тестировщик видит в измененных файлах sql скрипты.
Ожидание тестированияНа этом шаге могут быть задачи, которые уже были в тесте, а могут быть и в первый раз. Если задача уже в тесте была, то тимлид уже ответственным ставит именно того тестировщика, который вернул задачу в работу.
Иначе все задачи скапливаются у QA-лида. Он смотрит на пул задач и нагрузку каждого тестировщика, и определяет кому назначить задачу на тест. Более того, сразу же определяет и тестировщика для парного тестирования.
ТестированиеС данного шага, задачу можно перевести практически на любой шаг workflow. Тестировщик может:
Так же как и с шагом “В работе”, на этом шаге автоматически запускается счетчик времени, который логирует затраченное на работу время.
Ожидание парного тестированияЭтот шаг был придуман по нескольким причинам. Многие не понимали его целесообразности, но в итоге спустя какие-то время соглашались, что он необходим.
Суть его заключается в том, что есть основной тестировщик по задаче, который очень глубоко и усиленно ковыряет задачу со всевозможных аспектов и есть парный тестировщик, который поверхностно просматривает задачу только после полностью завершенных тестов первого. Это очень похоже на ревизию кода у программистов.
В итоге получаем то, что не только один тестировщик знает как устроена та или иная функциональность. Если задача футболялась 10 раз между программистом и тестировщиком, то свежий взгляд парного тестировщика может заметить что-то пропущенное. Ну и самое важное, то что каждый тестировщик работает по своему и привыкает использовать софт определенным образом (логинится не используя мышь, аплоадить файлы драг-н-дропом, вместо фильтров использовать сортировки, при вводе данных копипастить тексты и т.д.). Очень часто бывает, что одни и те же функции можно использовать по-разному, и парный тестировщик натыкается на ошибки, которые были проверены основным, но немного по-своему.
Парное тестированиеЕсли на этом шаге обычно уже можно считать, что задача почти закончена. И очень часто, когда поторапливают с выпуском версии, его можно пройти формально.
ReadMeПосле успешно проведенных тестирований уже окончательно определена функциональность и ее реализация. И вот теперь этой задачей занимается техпис. Обычно все задачи, кроме совсем незначительных или тех, которые сами сломали в процессе работы над версией, мы помечаем меткой “ReadMe”.
Парный тестировщик, если видит эту метку отправляет задачу на шаг “ReadMe” и назначает на техписа.
Техпис в специальном поле описывает очень кратко Release notes по этой задаче. Обычно это оповещение пользователя об изменении функциональности или исправлении ошибки, или о появлении новой функциональности и как ей пользоваться.
На этом же шаге техпис исправляет или дополняет справку ресурса в Confluence.
После проделанной работы, задача отправляется на финальный шаг “Ревизия функциональности”.
Ревизия функциональностиПри переходе задачи на этот шаг, триггеры Jira автоматом назначают ответственным ПМ-а.
На этом шаге ПМ проверяет работу всей команды в целом. Было ли реализовано то что хотели, именно так как хотели, нормальное ли описание в ReadMe и т.д.
Бывает, что на этом шаге оказывалось, что программист с тестировщиком что-то между собой порешали и отрезали “ненужную функциональность” или изменили ее потому что посчитали так лучше, и именно эта функциональность требовалась высшим руководством и именно в таком виде. Тогда задача опять идет на “Ожидание работ”.
Ценность данного шага заключается в том, что хороший ПМ или ДМ после выпуска и звонка заказчика с фразой “что вы наделали?”, должен знать как именно реализовали задачу, как назвали кнопки, тексты сообщений, нюансы алгоритмов и смело ответить “сам дурак”. А не мяться и гадать, а как же они сделали ту форму и чего в ней кнопка задизейблена…
ЗакрытоНу тут все и так понятно. Задача закрывается после удачно прошедшей ревизии функциональности.
Или задача в любой момент может оказаться никому не нужной, потому переход на этот шаг возможен с любого другого шага.
Рабочий столДля удобства в Jira были разработаны рабочие столы для каждого проекта с четырьмя гаджетами:

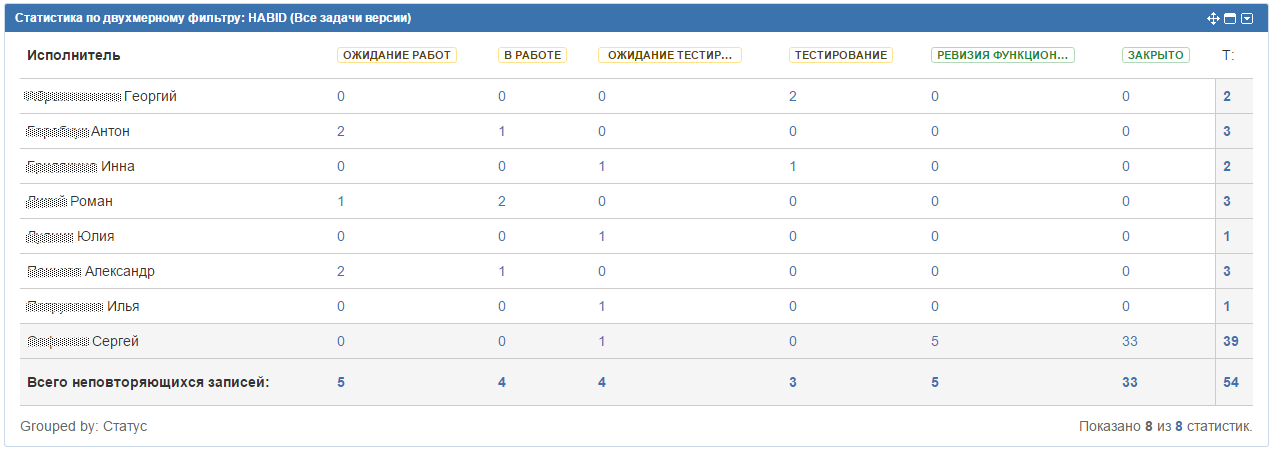
Еще с помощью GreenHopper я настроил такую доску:

Очень удобна для обзора всего процесса целиком.
Выпуск версииПри выпуске версии, мы выгружаем из Jira все задачи версии в виде двух колонок: компонент и поле ReadMe. Вот и получается у нас ReadMe сгруппированное по разделам.
С помощью “Scroll HTML Exporter” мы экспортируем страницу хелпа в Confluence и все ее дочерние страницы в набор html файлов, которые внутри выглядят так же красиво как в Confluence и ссылаются друг на друга.
ИтогиВот по такому workflow мы уже работаем несколько лет, иногда его дорабатывая и дотачивая.
Но в целом он очень удобен.
Для ПМ тем, что в любой момент времени видно кто именно и на каком шаге держит задачу.
Для разработчиков удобно видеть только свой объем работ.
Ну и конечно же автоматизация на всех шагах. Т.е. нет такого человека без которого рабочий процесс может остановиться.
[Из песочницы] Автоматизация workflow небольшой команды разработки (Часть 1)Пятница, 06 Ноября 2015 г. 13:01 (ссылка )
Практически во всех местах моей работы программистом для разработки использовали всего два продукта: багтрекинг и систему контроля версий. Чаще всего это были Atlassian Jira и SVN. В принципе, наличие этих двух систем здорово упорядочивает общение всех участников процесса разработки и положительно влияет на качество работы отдела и продукта.
Года 4 назад я морально, а затем и фактически дорос до уровня тимлида. Взгляды стали шире и выше текущих процессов. В голову стали приходить разные мысли о мотивации, оптимизации, автоматизации и прочих -циях. В этой статье я хотел бы поделиться опытом из разряда технических компетенций тимлида: как автоматизировать ежедневные процессы (например, автоматическая сборка продукта, выкладывание, документирование, управление правами т.д. и т.п.).
После третьей страницы текста моей статьи, я решил разделить ее на 2 блока:
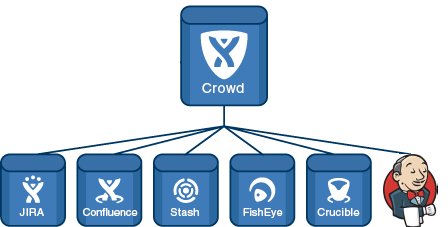
Первым был Crowd — менеджер учетных записей. Я скрестил и синхронизировал его с Jira. Crowd втянул в себя все группы и всех пользователей Jira. В Jira работу с директорией Crowd я сделал read/write (поскольку нового пользователя добавлять через Jira удобнее чем через Crowd).
В Jira всех пользователей разбил на группы:
Обязательная группа для всех пользователей.Только разработчики этого проекта.
В каждом проекте Jira позволяет настроить 3 роли. В роль USERS я занёс группу project1-users, в роль DEVELOPERS занёс project1-developers, а в роль ADMINISTRATORS занёс PM (менеджера проекта).
Если вкратце, то юзеры в группе могут только создавать задачки и наблюдать за ними, девелоперы могут их редактировать и решать, а админы управляют версиями, компонентами, могут удалять или редактировать чужие комментарии или задачи.
ConfluenceЯ считаю этот продукт самым удачным среди всевозможных баз знаний. После прочтения большого количества статей и сравнения разных систем, я пришел к выводу, что Confluence среди них бесспорный лидер.
В нем я создал разные Пространства:
Общие сведения по работе предприятия (параметры FTP хранилища, Wi-Fi, правила оплаты овертаймов, учета отпускных, контакты сотрудников, обсуждения корпоративов, инструкция по подключению принтера и т.д. и т.п.)Всё то, что в предыдущей группе только касаемо данного проекта (нюансы костылей, полезные sql запросы), юзерстори, постановки, входящие данные (дизайны, логотипы, иконки, параметры доступов), исходящие данные (ридми, инструкции, релиз ноутс), планы тестирования, описание механизмов, модулей, и т.д. и т.п.
Самое главное и приятное, что Confluence любую свою статью умеет красиво экспортировать автономные HTML страницы.
Весь хелп у нас хранится в Confluence в виде иерархической структуры статей. В конце версии одним кликом получается пачка HTML файлов, которые ссылаются друг на друга. Все это удовольствие мы просто копируем в проект и выпускаем. И потому справка у нас постраничная (а не все в одном огромном файле), легко поддерживаемая и всегда онлайн доступна для всей команды (а не где-то у кого-то в какой-то папке).
Каждый проект Jira и пространство Confluence связаны. В статье с постановкой есть ссылка на задачу и наоборот.
BitbucketДля хранения исходников мы исторически использовали SVN. Влияние новых технологий не прошло мимо, и конечно же выбор пал на git (бест практик как никак).
Поскольку я программист, а не сисадмин, установку чистого гита я не осилил. Потому взял готовый пакет GitBlit… но вскоре в нём разочаровался. В результате все перевёл на GitLab.
Год работы и 12 одновременно действующих проектов дали о себе знать. Сервер стал прогибаться под тяжестью руби. К тому же сказалась очень слабая совместимость с Atlassian продуктами.
В то время я заметил Stash. В чистом виде под линукс я, к сожалению, его не нашёл, за то поставил его в составе Bitbucket. И понеслась!
Создал проекты и по репозиторию в каждом. Дал полные права каждому ПМ-у на свой проект (теперь он сам может создавать репозитории в своём проекте сколько хочет). В репозитории на мастер ветку выдал права только лиду и по умолчанию выставил ветку dev.
Скрестил Bitbucket с Jira и теперь в каждой задаче есть список всех комитов по задаче. А из комитов можно переходить на задачки.
Fisheye and CrucibleГде-то я читал, что Crucible можно встроить в Stash. Но поизучав детально уже настроенный Bitbucket, я ничего подобного не нашёл. А так как CodeReview — обязательный этап в нашем Workflow, то пришлось ставить и Fisheye. Реально очень удобная штука, но имея Bitbucket, можно было обойтись и без неё.
Когда у нас стоял GitLab, добавлять репозитории в Fisheye было реально морочно… Куча настроек, генерация ключей, левые юзеры… С Bitbucket все пошло как по маслу. Скрестил Fisheye и Bitbucket и в Fisheye появился список всех репозиториев с кнопочкой “add”.
Создал проекты, указал в них группы разработки те, что в Jira для этих проектов, указал репозиторий и скрестил каждый со своим проектом в Jira. А в Jira наоборот указал в каждом проекте линки на Fisheye и Crucible и путь к репозиторию.
Теперь в каждой задаче есть комиты по задаче не только из Bitbucket, но и из Fisheye. Безтолково, конечно….но ничего страшного. Зато в каждой задаче теперь можно сразу увидеть Review и его статус!
JenkinsВот вроде бы и все, но нет! Надо же это все хозяйство как то автоматизированно собирать. Очень долго хотел прикрутить Bamboo, но он выглядит ущербно по сравнению с Jenkins. В Jenkins мне удавалось настроить автосборку всего еще и с перламутровыми пуговицами. В Bamboo все не так. Сообщество слабое, плагинов мало, можно рулить только выполнением консольных команд. Перечислять недостатки не буду. В начале настраивал под сборку Delphi-проектов, но потом перешли на веб и сборки стали простыми — вытащил, залил на ftp, отметил в Jira и письма разослал. Подумаю, может и на Bamboo перейдем.
Значит скрещивать Jenkins ни с кем не стал. Вроде как нужды нет. Никому не интересно в задаче сколько раз она собиралась. Единственное что — это в самом Jenkins поставил Jira plugin, чтобы при сборке задачи автоматически перемещались на другой шаг WorkFlow.
И важно все вышеперечисленные продукты обязательно настроить на Crowd. Единые учетки во всех этих системах — это реально удобно. При найме нового члена команды, достаточно его просто занести в Jira и указать его группу-проект и он имеет доступ ко всему. Точно так же и при увольнении. В одном месте выключил и доступа нет никуда.
Уголок сисадминаСервер у нас стоит Xeon X3430 4CPUs x 2,4 Ghz, 8 GB, 1TB
Вначале, я поднял Windows Server и на нем все эти продукты сразу + Ubuntu для GitLab. Сервер не осилил, раз в два часа просто зависал на 10 мин.
После этого принял решение разделить по разным виртуалкам. Вот что получилось:
Gateway — для выхода в Интернет (4 ядра, 4ГБ ОЗУ) — эта виртуалка мне уже досталась от админа, который этот сервер первоначально настраивал.
Jira — 2 ядра, 2ГБ ОЗУ
Confluence — 2 ядра, 2ГБ ОЗУ
Bitbucket&Jenkins — 2 ядра, 2ГБ ОЗУ
Crowd&FishEye&FTP — 2 ядра, 2ГБ ОЗУ
Все виртуалки на Linux Debian 8.2
Теперь все эти продукты летают, и зависаний, как раньше, нет.
На виртуалке Gateway пробросил два порта чтобы снаружи были доступны Jira и Confluence. Размышляю над тем, чтобы еще пробросить порт для доступа к Git. Но чтобы было более секурно, только ssh доступ.
ИтогиВот и готовы сервера и все необходимые продукты для полной автоматизации workflow разработки. В следующей части я постараюсь подробно описать как взаимодействуют эти все продукты ежедневно в процессе разработки.
P.S. Я посчитал ненужным описывать подробную настройку каждого продукта Atlassian из-за того, что статья стала бы очень длинной и сложной. Если у уважаемого сообщества будет желание ознакомиться с моим опытом, я с удовольствием опишу и эти нюансы настроек.
Пятница, 11 Сентября 2015 г. 12:41 (ссылка )
Много статей (в том числе и на Хабре) посвящено подключению к Git по SSH-ключам. Почти во всех из них используется один из двух способов: либо с помощью puttygen.exe, либо командами ssh-keygen или ssh-add.
Вчера на одном из компьютеров у меня не получилось сделать это для msysgit ни одним из описанных в интернете способов, и я потратил несколько часов на попытки настроить SSH-доступ, так ни чего и не добившись.
Как я решил эту проблему — под катом.
BitBucket всё время ругался на то, что ему требуется подключение с помощью ключа:
Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights and the repository exists.
Мои попытки сгенерировать ключи, указать пути в переменных среды, привязать ключи к гиту были бесполезны. Либо гит ругался крякозябрами (в случае ssh-agent cmd.exe ), либо просто игнорировал всё предложенное.
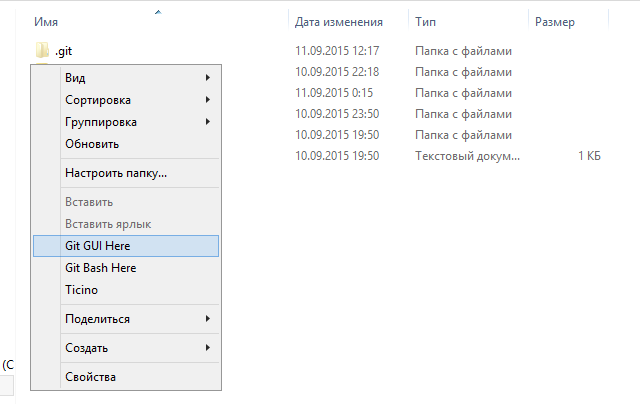
Решение оказалось куда удобнее и проще. Достаточно запустить в локальном репозитории GIT GUI Here, и в меню перейти в
Help ->Show SSH Key :
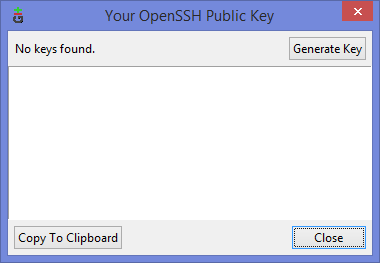
Если вы столкнулись с такой проблемой, то скорее всего у вас там ни чего не будет:
Окно генерации SSH Key
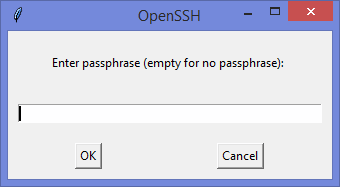
Ну а дальше читать будут, скорее всего, только самые педантичные… Жмём Generate key. видим окно запроса пароля (два раза) для приватного ключа:
И видим сгенерировавшийся публичный ключ:
Копируем его, и добавляем вэб-морду ГИТа (в моём случае это BitBucket; ключи там можно добавить в двух местах — в настройках аккаунта и в настройках проекта, нам первый вариант, ибо второй — для деплоя проекта) [Аккаунт ] — Управление аккаунтом — SSH-ключи — Добавить ключ :
Добавление ключа в BitBucket
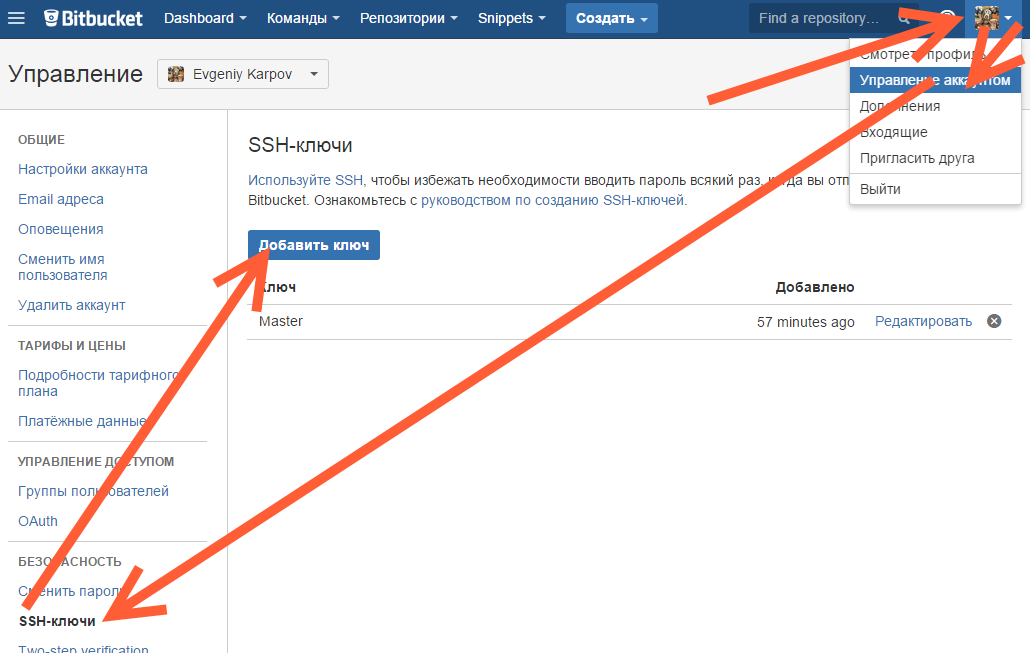
Ну, а дальше — просто делаем что нужно — или пуш, или клон (предполагается, что git remote add вы уже сделали сами). Git спросит, можно ли добавить хост к доверенным, и запросит passphrase (пароль приватного ключа). Всё, можно работать.
PS: Большое спасибо за наводку на решение моему коллеге Ивану!